这篇文章最初发表在 NVIDIA 技术博客上。
今天的机器学习( ML )解决方案很复杂,很少只使用一个模型。有效地训练模型需要大量多样的数据集,这些数据集可能需要多个模型才能有效地进行预测。此外,在生产中部署复杂的多模型 ML 解决方案可能是一项具有挑战性的任务。一个常见的例子是,不同框架的兼容性问题可能导致见解延迟。
一个易于服务于深度神经网络和基于树的模型的各种组合并且与框架无关的解决方案将有助于简化 ML 解决方案的部署,并在 ML 解决方案采用多层时对其进行扩展。
本文将讨论如何利用 NVIDIA 软件的多功能性处理不同类型的模型,并将它们集成到应用程序中。我将演示 NVIDIA RAPIDS 如何支持大型数据集的数据准备和 ML 训练,以及如何NVIDIA Triton Inference Server无缝服务于两个深度神经网络PyTorch和基于树的模XGBoost,用于预测信用违约。
以美国运通信用卡违约预测竞赛为例,我解释了如何在 GPU 或 CPU 上部署多模型解决方案,GPU 部署可以显著加快推理时间。这个解决方案在Kaggle 美国运通信用卡违约预测竞赛中的 4874 支队伍中排名前十。查看解决方案。
未来信用违约预测
信用违约预测是管理消费贷款业务风险的核心。美国运通,世界上最大的支付卡发行商,提供了一个工业规模的数据集,其中包含时间序列行为数据和匿名客户档案信息。该数据集高度代表了真实世界的场景:它很大,包含数值列和分类列,并且涉及一个时间序列问题。
成功解决这个业务问题的关键是揭示数据中的时间模式。
为什么要关注树和神经网络?
基于树的模型和深度神经网络被广泛认为是 ML 从业者最受欢迎的选择。
基于树的模型,如 XGBoost,主要用于表格数据集,因为它们可以处理嘈杂和冗余的特征,使得解释和理解预测背后的逻辑变得容易。
另一方面,深度神经网络擅长学习数据中的长期时间依赖性和序列模式。它们还可以从原始数据中自动提取特征。最近,深度神经网络被广泛应用生成高质量的新数据,利用它们从现有数据中学习分布的能力。
现在,我将描述我的团队如何在我们的 American Express 默认故障预测解决方案中使用此技术。
数据准备和部署的基本工具
当您准备一个复杂的 ML 模型时,有许多步骤可以准备、训练和部署一个有效的模型。 RAPIDS 和 Triton 推理服务器都支持 ML 过程中的关键阶段。
RAPIDS是一套开源软件库和 API,旨在加速 GPU 上的数据科学工作流程。它提供了用于数据预处理、机器学习和可视化的各种工具和库。在这种情况下,它可以在工作流开始时进行数据预处理和探索性数据分析。
NVIDIA Triton 是一种高性能的多模型推理服务器,支持 GPU 和 CPU,以支持部署。它可以轻松部署来自各种框架的模型,例如TensorFlow,PyTorch和ONNX,详情请参阅此处。
NVIDIA Triton 支持树形模型,如 XGBoost、LightGBM等,使用Forest Inference Library 后端。这使得它非常适合我们正在编写的模型。
问题概述
其目的是利用客户过去的月度客户档案数据预测客户未来是否会拖欠信用卡余额。二元目标变量,默认或无默认,由客户是否在对账单日期后 120 天内偿还其未偿信用卡余额决定。
图 1 显示了问题和数据集的概述,突出了信用违约预测的关键方面和数据集特征。测试数据集庞大,有 900K 个客户, 1100 万行, 191 列,包括数字和分类特征。
目标是创建一个模型,该模型可以基于数据集中的其他变量和要管理的任务关键时间值来预测分类二元变量。在建模之前,这个大型数据集需要进行重要的特征工程,使其成为 RAPIDS cuDF 数据准备的理想候选者。数据集的大小对实时推理提出了进一步的挑战,高性能 NVIDIA Triton 服务器解决了这一问题。

图 1 。问题概述:美国运通违约预测竞赛
方法
我们将模型开发过程分解为一系列步骤:
- 数据集准备
- 功能工程
- 数据集探索
- 自回归递归神经网络( RNN )模
- 数据集性能
数据集准备
给定的美国运通数据是一个时间序列,由按客户 ID 和时间戳排序的客户的多个档案组成:
- 数据集中的每一行代表一个客户 1 个月的配置文件。
- 每个客户在数据中有 13 个连续的行,这些行表示他们在连续 13 个月内的配置文件。
- 数据中有 214 列。
- 列是匿名的,除了
customer_id和month,并分为以下一般类别:拖欠、支出、付款、余额、风险
表 1 总结了每个类别中的列数。除了其类别之外,没有关于每一列的含义的信息。这些匿名列大多是浮点数。
| 客户 id | 月 | 犯罪 | 花费 | 付款 | 均衡 | 危险 | |
| #共列 | 1 | 1 | 106 | 25 | 10 | 43 | 28 |
表 1 。每个类别中的列数
对于训练数据,无论是否默认,基本事实都存储在另一个表格数据中,其中每个客户对应一行。共有两列:customer_id和default.
与 RAPIDS cuDF 的特征工程
该项目始于特征工程,为模型准备时间序列数据集。众所周知,时间序列数据需要大量处理,而对于基于 CPU 的数据科学解决方案来说,这变得更加困难。为了有效地运行这一阶段的数据准备,我们利用 GPU 的力量RAPIDS cuDF。
我们将每个客户档案的月数减少到数据集中的最后一个月,重点是将数据集精简为最重要的数据点。上个月在预测未来默认事件方面具有最高的相关性,并将行数减少到 900K 。这是由drop_duplicates(keep=’last’)在 cuDF 中。
RAPIDS cuDF 可以通过为每个创建差异和聚合特征来进一步帮助加速customer_id价值虽然 RAPIDS cuDF 用于在前面的笔记本中设计额外的功能,但我忽略了这些功能,以保持这个单一的 GPU 演练的简单性。
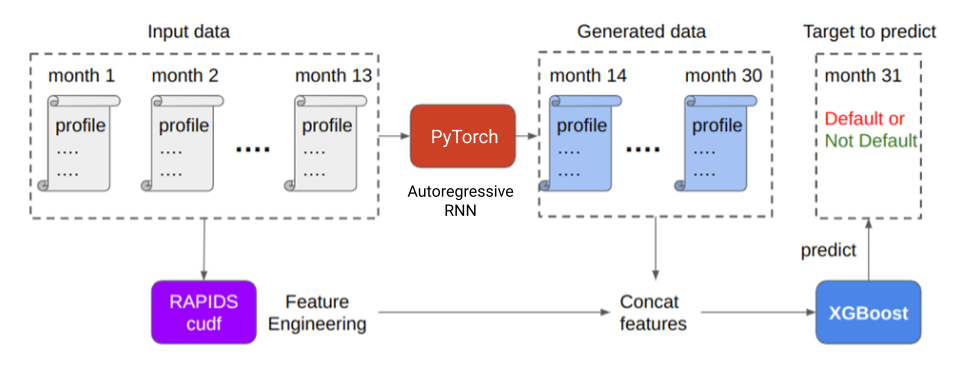
图 2 :解决方案概述
探索数据集
每个客户档案的功能都是在第 13 个月测量的,而默认检查的日期是第 31 个月。考虑到违约客户的数据集中有 17 个月的时间间隔,该团队为缺失的月份(第 14 个月至第 30 个月)生成了新的客户档案,以提高模型的预测率。该团队在直观地探索数据后受到启发,实现了自回归 RNN 技术。
想了解更多关于识别自回归 RNN 技术的信息,请参阅Amex EDA 数值特征随时间的演变笔记本。
在探索数据集时,团队将数据可视化为图表。图 3 绘制了列的子集随时间的变化趋势。 x 轴表示月份, y 轴表示列名。
例如,左上角的子图显示了拖欠类别的第 53 列 D _ 53 列在几个月内的变化情况。红色虚线是正样本的 D _ 53 列的平均值,其中 Default = True ,绿色实线分别是负样本的平均值。
对于大多数列,都有明显的时间模式。可以训练模型来推断和预测列的未来值。使用此模型,为数据集生成附加值有助于提高模型的可预测性。

图 3 。专栏随时间变化的趋势(来源:Amex EDA evolvement of numeric features over time)
当您计划增强数据集时,另一个关键是每列的模式可能不同。线性趋势、非线性趋势、摆动和更多的变化都是可以观察到的。数据生成模型必须是通用的、灵活的,可以学习和概括所有这些不同的模式。
用自回归 RNN 模型生成新的简档
基于这些数据特征,我们的团队提出了一个自回归 RNN 模型来同时学习所有这些模式。自回归的意味着当前时间步长的输出是下一个时间步长的输入。图 4 显示了自回归生成的工作原理。

图 4 。自回归生成动画(来源:WaveNet)
RNN 模型的输入是当前月份的客户档案,包括所有 214 列。 RNN 模型的输出是下个月的预测客户概况。该方法中使用的自回归 RNN 是以自我监督的方式进行训练的,这意味着它只使用客户档案进行训练,不需要“默认与否”目标列。
这种增强数据集的自我监督训练使您能够使用大量未标记的数据——这在现实世界的应用中是一个显著的优势,因为标记的数据通常很难获得,而且成本很高。
新数据集的性能
RNN 可以准确地预测未来的概况。均方根误差用于地面实况剖面和预测剖面之间。将 RNN 与简单的基线进行比较,并假设未来的剖面与上次观测到的剖面相同。
| 自回归 RNN | 上次观察到的剖面基线 | |
| 所有 214 列的 RMSE | 0 . 019 | 0 . 03 |
表 2 。比较自回归 RNN 和基线的 RMSE 值(越小越好)
在表 2 中, RNN 将 RMSE 从 0 . 03 降低到 0 . 019 (提高了 33% )。这是对原始数据集的显著增强。
图 2 显示,生成用于训练的数据集的最后一步是将最后的概要文件和生成的概要文件组合成一个矩阵。使用 RAPIDS cuDF 中的联接函数执行此操作,并将它们提供给下游 XGBoost 分类器以预测默认值。生成的配置文件大大提高了模型的性能。
表 3 显示,通过组合最新的配置文件和生成的未来配置文件,XGBoost 分类器可以更准确地预测未来默认值 0.003。这是对默认检测问题的显著改进,可能会使解决方案在 美国运通信用卡默认预测竞赛 中取得更好的成绩!
| xgb 在上次配置文件上进行了训练 | xgb 在最后的配置文件和****自回归 RNN 生成的简档 | |
| American Express metric用于预测违约 | 0 . 7797 | 0 . 7830 |
表 3 。通过比较 XGBoost 是否具有自回归 RNN 生成的特征来评估默认预测(越大越好)
将模型部署到 Triton 推理服务器
图 5 显示,在推理过程中, NVIDIA Triton 推理服务器能够在 GPU 或 GPU 上托管 PyTorch 中实现的自回归 RNN 模型和 XGBoost 中实现的基于树的模型。
首先,将预训练的 PyTorch RNN 模型和 XGBoost 模型保存在具有正确文件夹层次结构的单独文件夹中。接下来,为每个模型编写配置文件。 PyTorch 模型处理这批输入数据以生成未来的简档,然后将级联的简档输入 XGBoost 模型以进行进一步推断。
在不到 6 秒的时间里,已经推断出 115K 个客户档案rnn-xgb管道上的单个 GPU 。

图 5 。具有 NVIDIA Triton 推理服务器的自回归 RNN 和 XGBoost 模
即使有这种复杂的模型管道,包括 13 个时间步长的自回归 RNN 和用于分类的 XGBoost ,推理时间也非常快。在 1130 万美国运通客户档案上运行 NVIDIA Triton 推理服务器管道,在单个 NVIDIA V100 GPU 上只需 45 秒。
总结
本文中提出的信贷违约预测解决方案成功地利用了深度神经网络和树模型的力量,通过补充数据来提高预测的准确性。
RAPIDS cuDF 使时间序列数据的数据处理更容易、更快。模型的部署与 Triton 推理服务器无缝衔接,该服务器可以在 CPU 或 GPU 上托管深度神经网络和树模型。这使它成为实时推理的强大工具。
该演示还突出了 GPU 和 Triton 推理服务器在信用违约预测中应用高性能计算能力的潜力,为金融服务领域的进一步探索和改进开辟了途径。
本文使用 notebooks:
