提示:本文不要求一定要有python基础,但是如果想要在机器学习领域继续研究下去的话,建议把基础打好一步一步来。
前言
有很多刚入门机器学习的像我一样小白想要训练一个自己的目标检测模型,但是却不知从何下手,本文是我自己训练模型的一个全部过程,可以说是能帮助你少走很多弯路,也可以帮你节省很多查阅资料的时间,毕竟这些都是我踩过的坑,我也是跟着这位大佬做的,在这里表示万分感谢,那么废话不多说,我们直接开始。本篇文章基于windows
我做的这个项目是基于yolov3的安全帽检测,项目源码我放在了GitHub上,有需要参考的小伙伴可以在下面评论或者给我私信,把你的github名称或者邮箱告诉我(我需要添加一下才能正常打开),稍后自取(具体在master这一分支之下,并没有在main主分支下,这一点需要注意)
==注意==:在这一整个过程当中难免会遇到报错的情况,但是你要明白报错是告诉你你哪里有问题,==报错的是信息并不是乱码==,不少小伙伴一看到报错就慌了,我只想说没关系的,这其实是正常现象,你可以把报错的信息复制到浏览器里进行搜索,95%以上的问题都可以通过这一方法来解决。
一、安装Anaconda
直接去官网下载,注意自己的系统
Anaconda官网
下载之后安装即可,注意安装的时候安装的文件夹要是空的
二、程序下载
(1)yolov3下载
进入github搜索 yolov3
1、在这里我们可以选择不同的yolov3的版本
2、点击右边的【download】即可开始下载压缩包
3、下载完成之后按照自己的习惯进行文件的解压缩(注意文件路径中不要出现中文)
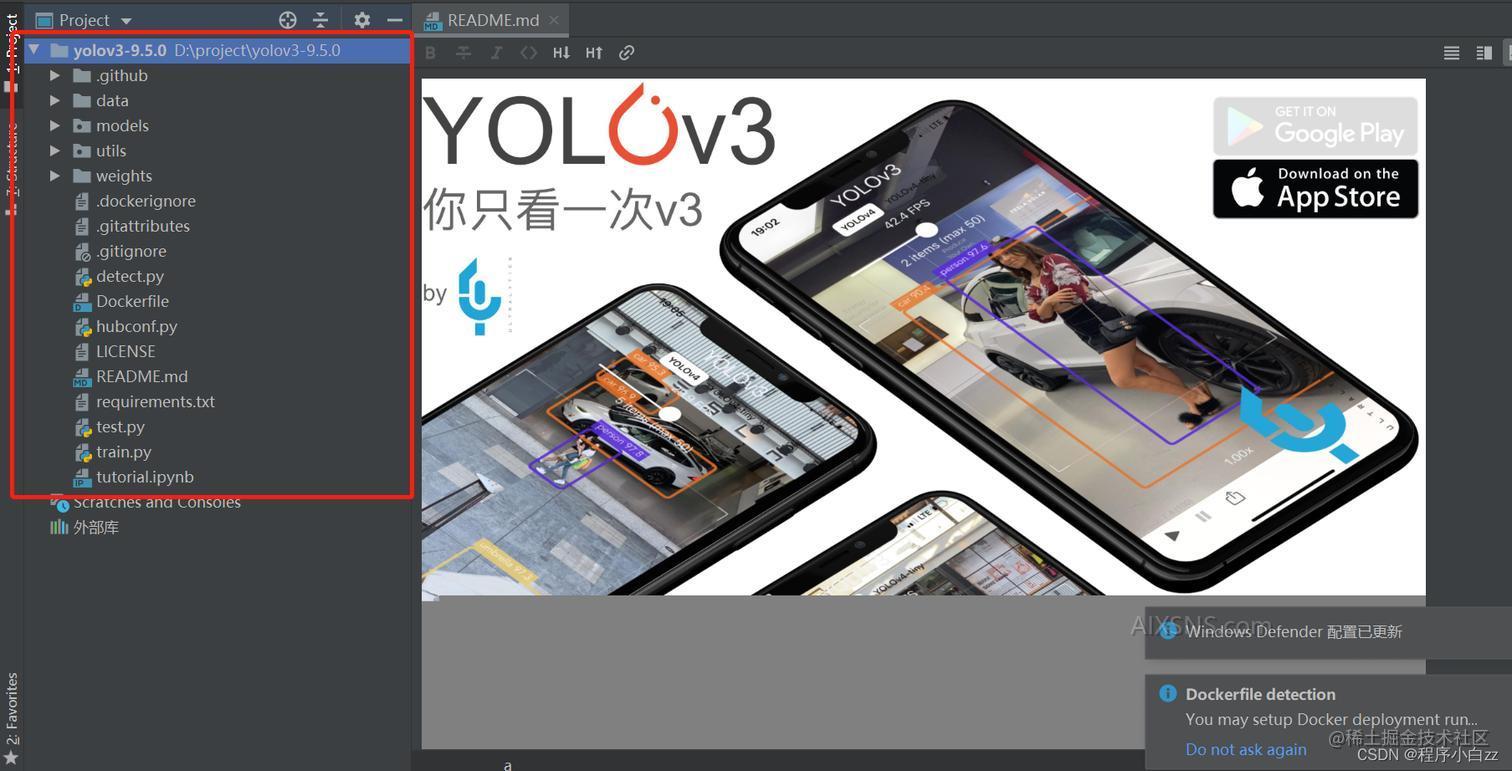
4、用pycharm打开yolov3的工程文件,结果如下图
(2)训练集文件夹的创建
1.在yolov3-9.5.0工程文件夹下,新建一个名称为VOCdevkit的文件夹
2.在VOCdevkit文件夹下,新建三个名称分别为images,labels,VOC2007的文件夹
3.在images和labels文件夹下分别新建两个名为train和val的文件夹
4.在VOC2007文件夹下新建三个名称分别为Annotations,JPEGImages,YOLOLabels的文件夹
(注意:也可以参考其他博主创建文件的方式,我这样创建会与我之后的转标签格式和分配训练集、验证集的脚本文件中的路径对应)
结果如下图:
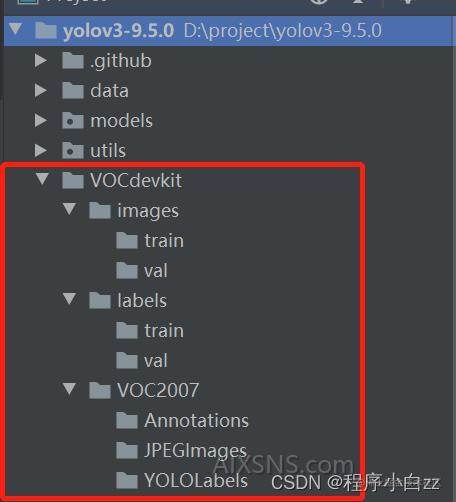
Annotations:.json标签文件夹
JPEGImages:图片文件夹
YOLOLabels:txt标签文件夹(yolov训练需要txt格式的标签文件)
(3)预训练权重下载
我们并不是完完全全从0开始训练一个模型,我们会先借助预训练权重进行训练,这样可以一定程度上缩短模型的训练时间同时会提升模型训练的精度。预训练的权重越大,训练出来的精度就越高,相应其检测速度会受到影响。
1、下载yolov3权重
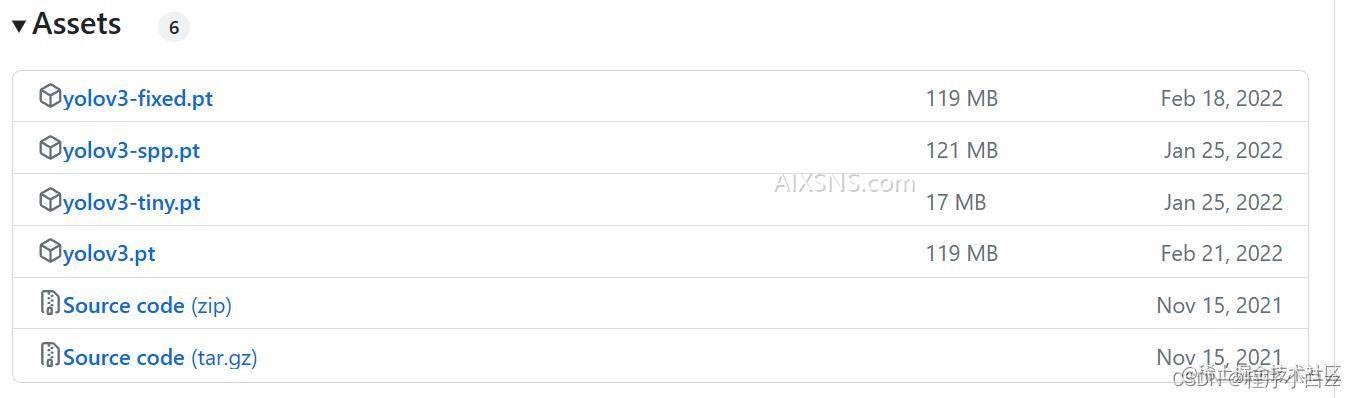
我这个任务比较小,所以我选择了-tiny-的权重,在之后我们要使用对应的yaml文件
2、将下载好的权重放到weights文件夹中
三、环境准备
(1)检查cuda版本
1.按下win+R,输入cmd并按下回车,打开命令台,输入下面的命令来查看cuda版本
nvidia-smi
在这里我们可以看到显卡驱动版本为512.72,最高支持的cuda版本为11.6,我们之后会根据最高支持的cuda版本安装pytorch

可以参考下面这一表格(没有列举到的请自行查阅)
| torch版本 | cuda版本 | 所需python版本 |
|---|---|---|
| 1.13.1 | cu116 | 3.7、3.8、3.9、3.10 |
| 1.13.0 | cu116 | 3.7、3.8、3.9、3.10 |
| 1.12.1 | cu113 | 3.7、3.8、3.9、3.10 |
| 1.12.0 | cu113 | 3.7、3.8、3.9、3.10 |
| 1.11.0 | cu113 | 3.7、3.8、3.9、3.10 |
| 1.10.2 | cu113 | 3.6、3.7、3.8、3.9 |
| 1.10.1 | cu113 | 3.6、3.7、3.8、3.9 |
| 1.9.1 | cu111 | 3.6、3.7、3.8、3.9 |
| 1.9.0 | cu111 | 3.6、3.7、3.8、3.9 |
| 1.8.1 | cu111 | 3.6、3.7、3.8、3.9 |
| 1.8.0 | cu111 | 3.6、3.7、3.8、3.9 |
| 1.7.1 | cu110 | 3.6、3.7、3.8、3.9 |
| 1.7.0 | cu110 | 3.6、3.7、3.8 |
通过表格我确定我的torch版本选择1.13.3,cuda版本为cu116,python版本为cp38
(2)安装pytorch
1、准备一个虚拟环境
打开anaconda prompt

输入下面的命令,创建一个名为demo并且python版本为3.8的虚拟环境(名称和python的版本随意,但是要记得自己的python版本)
conda create -n demo python=3.8
输入 y 并按下回车 ,等出现下图的信息
之后我们输入下面的命令来激活虚拟环境
conda activate demo

当括号里由base变成demo说明创建成功。
2、下载pytorch
下载pytorch有很多种方式,这里我介绍一种虽然不是最简单但成功率几乎100%的方法
首先,我们进入pytorch的官网
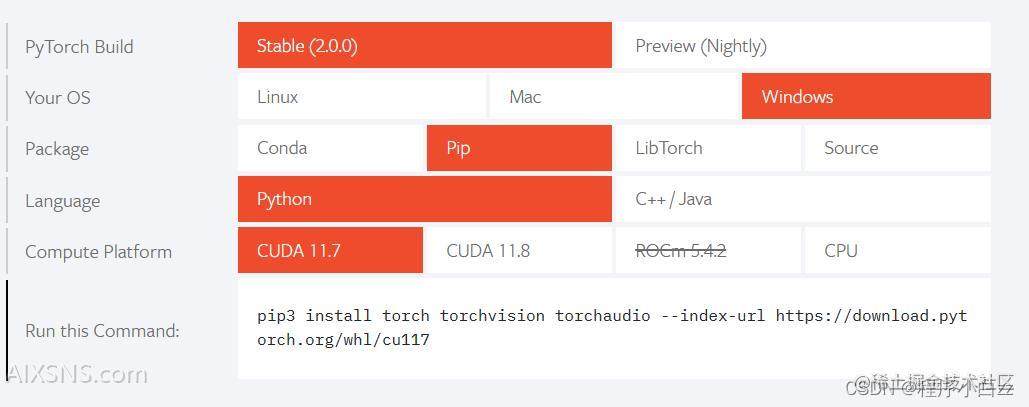
我们可以看到官方提供的安装方式是复制下图中的命令行,用这种方式可能会出现下载太慢的情况,所以我们不采用这种方式。注意看,这个命令其实告诉我们,下载的其实是后缀为.whl的文件,我们暂且称它为“车轮文件”,所以我们可以直接下载车轮文件到我们的电脑上,之后再从电脑上安装下载好的车轮文件。
根据我们在上面步骤中确定的torch版本,点击这一项查看往届版本
找到我们所需的torch版本,注意在这里一会我们要下载三个车轮文件,分别是 pytorch=1.13.0 torchvision=0.14.0 torchaudio=0.13.0,明确这一点之后我们进入车轮网站(也是官方网站大家放心下载)。
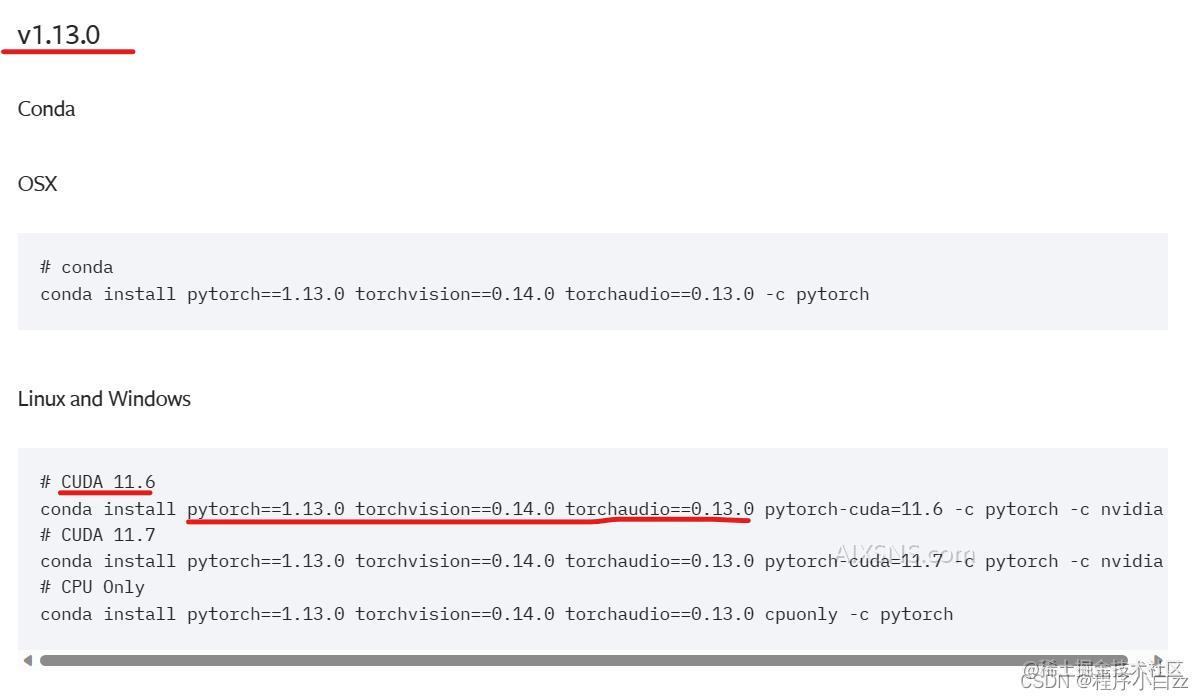
如果链接打不开,我们稍微往下一点找到这个
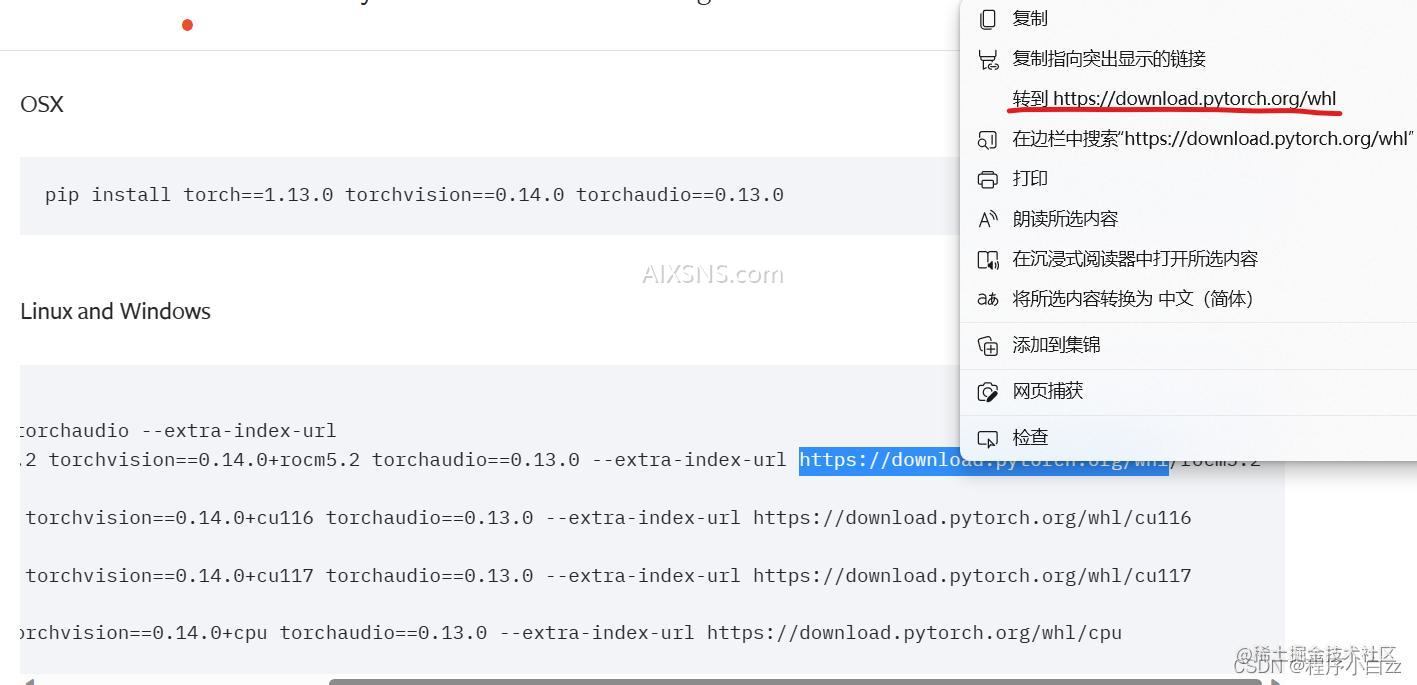
点击右键选择转到即可
进入之后我们要分别进入这三个链接分别下载pytorch=1.13.0 torchvision=0.14.0 torchaudio=0.13.0(再次注意这是我对应的版本,不要直接照搬)
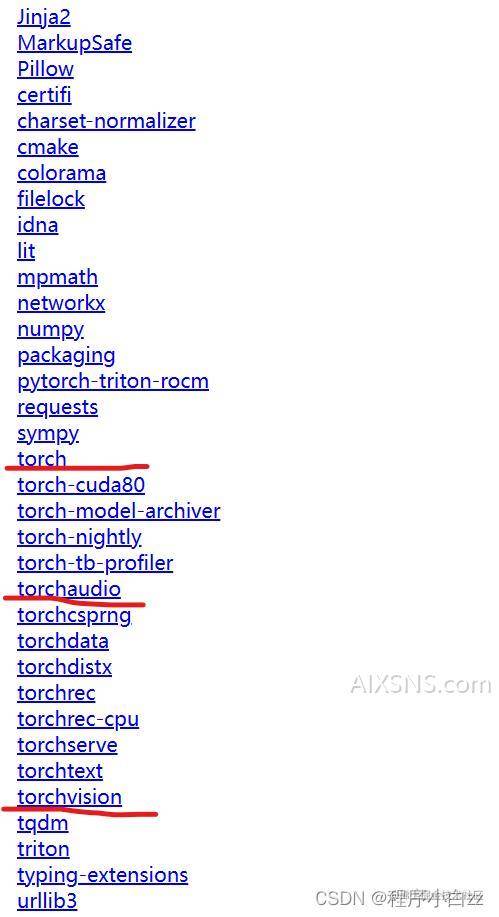
这里我拿torch举例,进入之后按ctrl+f进行搜索,输入 torch-1.13.0+cuda116-cp38,就可以锁定两个,我们点击win系统的下载即可,其余两个下载方法类似我就不赘述了,==这里千万要注意版本对应下载好==
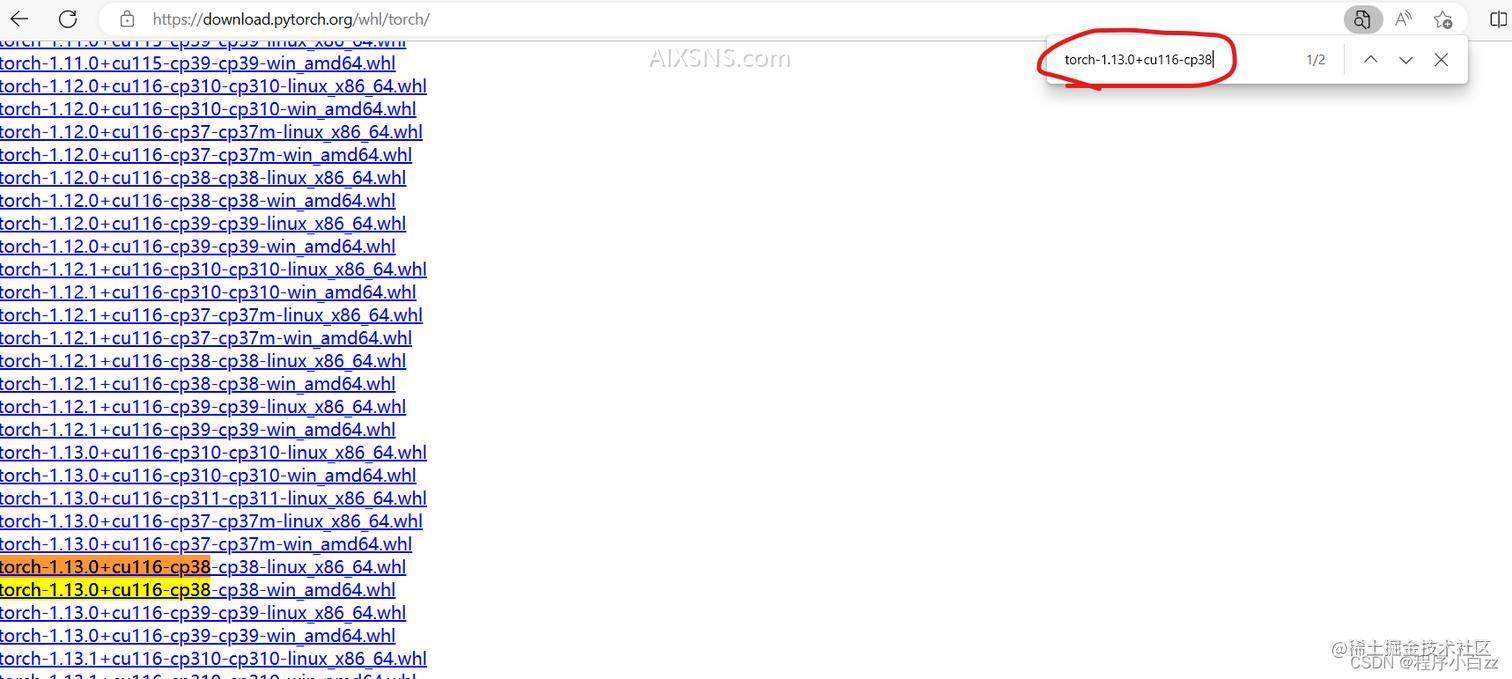
之后我拿下载好的torchaudio来做演示,其他两个大家同理即可
下载好之后右键点击属性,将他的位置复制下来
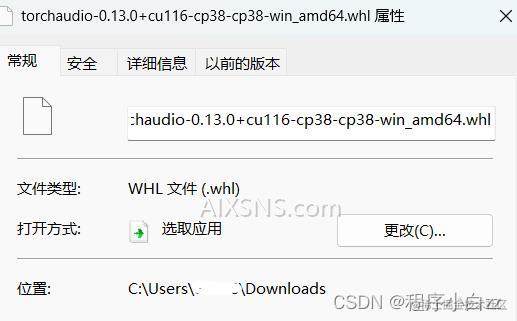
进入我们之前创建好的虚拟环境中(conda activate demo)输入下列命令
(这里每个人保存文件的路径都不一样,你只需要明白是路径加上文件名就行)
pip install C:Users*****Downloadstorchaudio-0.13.0+cu116-cp38-cp38-win_amd64.whl

等待下载完成即可,三个文件都是这样的操作。
3、验证pytorch是否安装完成
进入虚拟环境中,输入python回车,再输入import torch回车,若安装失败会返回“No module named torch”,若成功则不会返回任何东西,我们继续输入 torch.cuda.is_available(),返回true即为安装成功。
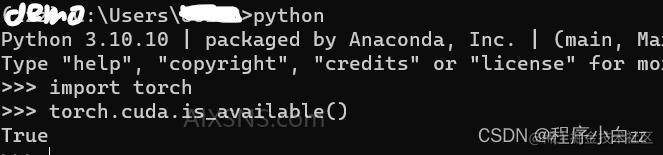
不用在意我的虚拟环境名字,这里我偷了个懒用了我已经配置好的环境给大家做演示(同时下文中所有的环境都会是zzz,大家按照自己的来就可以)。
(3)向pycharm中导入pytorch
1、打开pycharm,新建一个工程
2、依次点击文件、设置、项目下的python解释器
在这里选择已经有的我们之前创建好的虚拟环境的解释器

如果这里没有的话,就选择后面的【添加解释器】这一选项,选择Conda环境–>使用现有环境–>选择我们之前创建的虚拟环境,然后点击确定

之后先点击应用,再点击确定

(4)验证pytorch安装完成
新建一个python文件,输入以下的代码并运行
代码如下(示例):
import torch
a = torch.cuda.is_available()
print(a)
ngpu= 1
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3,3).cuda())
如果运行结果如下图,则说明已经成功安装了pytorch

四、制作自己的数据集
(1)安装labelme
首先我们在Anaconda Prompt 中激活我们之前创建的虚拟环境,输入以下的命令来安装labelme这一标签标注工具(当然大家也可以选择其他的标注工具)
pip install labelme
(2)标注标签
之后使用的时候直接输入labelme即可。打开工具如下图,

【Open】用来选择所要标注的单个图片的位置
【Open Dir】用来选择整个文件夹的位置
【file】–>【change output dir]可以更改保存标签的位置
另外比较好用的是file菜单下的save automatically,选择这个之后便可以自动保存了。
下面给大家作以示范,在edit菜单下选择create rectangle会使用矩形框进行标注

输入标签类型,点击ok,即可完成标注

总体来说,这一过程非常简单,但也非常枯燥,大家可以自行体验。
(3)进行标签类型转换
我们使用labelme标注的标签格式是.json格式的,而yolo所接受的标签格式为.txt的(如果你的标签是.xml格式的就得麻烦你自己查阅一下转换代码了),同时我们也会将里面的内容做一定的转换,这里的原理就不在这里赘述了,大家感兴趣的话可以自行查阅。
下面是标签转换的程序,大家新建一个python文件,千万注意:如果你是按照我上面说的方式创建了相应的训练集文件夹之后只需要修改标签类型即可使用了
import json
import cv2
from pathlib import Path
all_classes={'person':0,'hat':1} ##注意这里修改为你自己的标签类型
savepath='yolov3-9.5.0\VOCdevkit\VOC2007\YOLOLabels\'
jsonpath='yolov3-9.5.0\VOCdevkit\VOC2007\Annotations\'
imgpath='yolov3-9.5.0\VOCdevkit\VOC2007\JPEGImages\'
path1=Path(jsonpath)
json_files=path1.iterdir()
for i in json_files:
infile=i
with open(infile,'r') as load_f:
load_dict = json.load(load_f)
path2=Path(savepath+load_dict['imagePath'][13:-4]+'.txt')
with path2.open('w',encoding='utf8') as outfile:
img_path=imgpath+load_dict['imagePath'][13:]
img=cv2.imread(img_path)
size=img.shape
high_size=size[0]
width_size=size[1]
for item in load_dict['shapes']:
label_int=all_classes[item['label']]
if not item['points']:
continue
x1,y1,x2,y2=item['points'][0][0],item['points'][0][1],item['points'][1][0],item['points'][1][1]
x_center=(x1+x2)/2/width_size
y_center=(y1+y2)/2/high_size
w=abs(x2-x1)/width_size
h=abs(y2-y1)/high_size
outfile.write(f'{label_int} {x_center} {y_center} {w} {h}n')
(4)划分训练集和验证集
我们可以根据2:8或者1:9的比例将我们的数据集划分成验证集和训练集,划分代码如下:
from pathlib import Path
import random
import shutil
def moveimg(file_images_all,file_images_val,file_images_train):
path1=Path(file_images_all)
image_path=path1.iterdir()
image_list=list(image_path)
filenumber=len(image_list)
rate=0.1
picknumber=int(filenumber*rate+1) ##这里我们加上1,防止在数据量很小的时候报错,但这在正式项目中一般是不会存在的
sample=random.sample(image_list,picknumber)
for name in sample:
shutil.move(name,file_images_val)
for images in path1.rglob('*.jpg'):
shutil.move(images,file_images_train)
return
def movelabel(file_list,file_label_all,file_label_val,file_label_train):
for i in file_list:
if str(i).endswith('.jpg'):
filename=f'{file_label_all}\{str(i)[-9:-3]}txt'
path3=Path(filename)
if path3.exists:
shutil.move(filename,file_label_val)
for i in Path(file_label_all).rglob('*.txt'):
shutil.move(i,file_label_train)
if __name__=='__main__':
file_images_all='yolov3-9.5.0\VOCdevkit\VOC2007\JPEGImages\'
file_iamges_val='yolov3-9.5.0\VOCdevkit\images\val'
file_images_train='yolov3-9.5.0\VOCdevkit\images\train'
moveimg(file_images_all,file_iamges_val,file_images_train)
path2=Path('yolov3-9.5.0\VOCdevkit\images\val\')
file_list=list(path2.iterdir())
file_label_all='yolov3-9.5.0\VOCdevkit\VOC2007\YOLOLabels'
file_label_val='yolov3-9.5.0\VOCdevkit\labels\val'
file_label_train='yolov3-9.5.0\VOCdevkit\labels\train'
movelabel(file_list,file_label_all,file_label_val,file_label_train)
到此为止我们所有的前期准备工作都已经做完了,下面我们开始模型的训练
五、模型训练
(1)将pytorch应用到工程
用pycharm打开我们解压好的yolov3的文件,点击文件–>设置找到【Project Interpreter】将我们之前创建的环境,点击应用,之后点击确定
(2)requirements中依赖包安装
这里我说两种方式
第一种是打开requirements.txt文件
然后进入我们的虚拟环境中按照文件中的要求一个一个去安装
这样虽然慢但是出错的概率很低,因为可能一些包由于版本原因已经不兼容了。
第二种是先找到并打开requirements.txt文件
复制文件中的命令行

之后点击终端

在终端中粘贴,并按回车运行命令行便可以开始安装依赖包了。
如果有报错,记得报错不是乱码,自行百度搜索解决问题
(3)修改数据配置文件
1、找到data目录下的voc.yaml文件,将这个文件复制一份,并将复制的文件重命名,这里我改为hat.yaml(这里因为我的项目与安全帽有关,所以我这样命名了)

2、进入hat.yaml文件中,我们需要做一些修改:
(1)将download语句注释掉
(2)修改train、val的路径,改成自己文件的路径,注意:在这里建议写绝对路径会少出很多问题
(3)修改nc(number of classes)为自己数据集中的标签种类个数
(4)修改names为自己数据集中的标签种类

(4)修改模型配置文件
因为我们之前下载的权重文件为yolov3-tiny.py,所以我们现在需要找到与之相匹配的.yaml文件
1、在models目录中我们选择将yolov3-tiny.yaml文件复制一份并重命名为自己项目的名字,这里我改为yolov3-tiny_hat.yaml

2、进入yolov3-tiny_hat.yaml文件,将第一行的 nc 修改为自己数据集中的标签种类的数量

(5)修改train.py主函数
我们主要修改以下几个参数:
①. -weights: 初始化的权重文件的路径
②. -cfg: 模型yaml文件的路径
③. -data: 数据yaml文件的路径
④. -epochs: 训练的次数
⑤. -batch-size: 一轮训练的文件数(具体设置与电脑的gpu有关)
⑥. -workers: cpu线程(这里我设置为0)

(6)运行 train.py
开始模型训练(这里我截的是第87次训练的结果)

六、模型训练中遇到的问题
如果有报错,记得报错不是乱码,自行百度搜索解决问题
1、错误 OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
这里需要我们进入到我们对应建立的虚拟环境的文件夹中搜索 ’libiomp5md‘可能会出现两个,我们删除一个即可(这里建议做备份,以备之后找补)
2、RuntimeError: result type Float can’t be cast to the desired output type __int64
我参考了这一篇文章 blog.csdn.net/Thebest_jac…
这里我们先进入【utils】文件下的【loss.py】
按ctel + f 打开搜索功能,输入【for i in range(self.nl)】找到下面的一行内容:

将下面的代码替换掉上图的红圈部分:
anchors, shape = self.anchors[i], p[i].shape
按【Ctrl】+【F】打开搜索功能,输入【indices.append】找到下面的一行内容

将下面的代码替换掉上图的红圈部分:
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
3、模型训练在第一个epoch卡死
解决办法就是上文中说到的将 workers 这个代表多线程的的参数改成0
这里就是我遇到的一些问题,这里再次提醒大家
如果有报错,记得报错不是乱码,自行百度搜索解决问题
七、测试训练结果
打开detect.py文件找到这一行代码

(1)照片和视频
直接将【default】后改成要检测的图片或是视频的路径即可
(2)调用摄像头进行实时检测
先在【utils】文件中找到【datasets.py】文件,进入后将这两处改成str类型

之后再将【default】的参数改成0即可,如上图
总结
以上就是本篇文章的全部内容,本文也是本人在训练模型过程中的一次项目日志,因为在这一整个过程中由于种种原因,我踩了不少坑,所以才会将这整个过程进行汇总,然后分享出来与大家一起学习,再次感谢这位老师大家可以多去看看他的文章真的巨强,本人也是机器学习的初学者,所以文章中难免会有疏忽的地方,如果有错误请大家积极指出,十分感谢大家的支持,再次愿大家都可以训练出自己的模型。最后再次提醒大家:如果有报错,记得报错不是乱码,自行百度搜索解决问题
