关键词:FCN 、 CNN 、 CVPR2015、 语义分割
论文:Fully Convolutional Networks for Semantic Segmentation
前言
《Fully Convolutional Networks for Semantic Segmentation》(后续将以《FCN》替代)是由Jonathan Long、Evan Shelhamer和Trevor Darrell等人在2015年发表的论文。该论文提出了一种基于全卷积神经网络(FCN)的语义分割方法,将传统的卷积神经网络中的全连接层替换为卷积层,从而实现了端到端的像素级别的语义分割,这是第一个端到端训练fns进行像素预测和进行超级预训练的工作。现有网络的全卷积版本可以从任意大小的输入预测密集输出。
论文背景和意义
Semantic Segmentation 是计算机视觉领域中的一个重要研究方向,它通过将图像分割成不同的类别,实现对图像中物体的识别和分割。在过去的几年中,深度学习在计算机视觉领域取得了巨大的进展,其中卷积神经网络 (Convolutional Neural Network,CNN) 已经成为了 Semantic Segmentation 最常用的方法。
然而,传统的 CNN 方法需要大量的人工标注数据,而标注数据的成本非常高。因此,对于某些场景,如夜间驾驶、医学影像等,传统 CNN 方法难以应用。而 Fully Convolutional Networks(FCN) 的出现,为解决这一问题提供了新的思路。
全卷积网络可以有效地学习对每像素任务(如语义分段定位)进行密集预测
主要内容和贡献
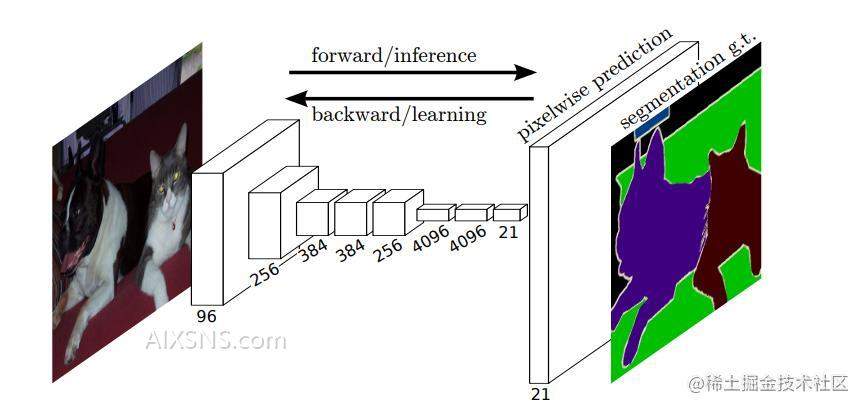
《FCN》的主要贡献在于提出了一种全卷积神经网络(Fully Convolutional Network,FCN)的架构,用于解决语义分割问题。传统的卷积神经网络(CNN)通常被用于图像分类问题,即将整张图片分为不同的类别。但是对于像素级别的语义分割问题,传统的CNN架构并不适用,因为它们的输出通常是一个固定大小的向量,无法处理不同大小的输入图像。
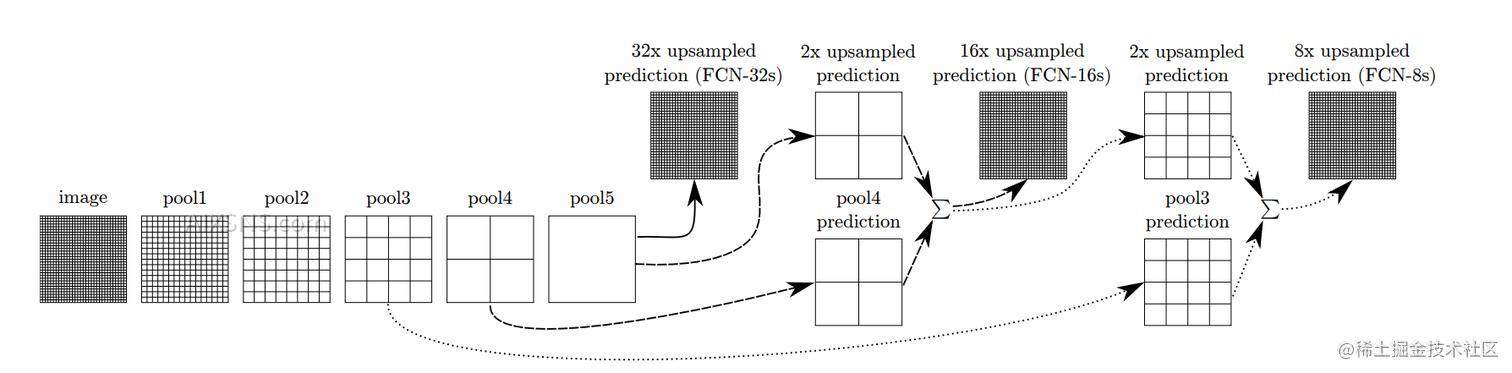
FCN的主要思想是将传统的卷积层和池化层替换为全卷积层,使得网络的输出可以是一个与输入图像大小相同的特征图。这样,每个像素都可以被预测为属于哪个类别,从而实现像素级别的语义分割。同时,FCN还使用了上采样和跳跃连接等技术,帮助网络更好地捕捉不同尺度的特征信息,提高了分割的准确性。
代码
在这里我们以FCN8为例子展示:
import numpy as np
import torch
import torch.nn as nn
def get_upsample_filter(size):
factor=(size+1)//2
if size%2==1:
center=factor-1
else:
center=factor-0.5
og=np.ogrid[:size,:size]
filter=(1-abs(og[0]-center)/factor)*(1-abs(og[1]-center)/factor)
return torch.from_numpy(filter).float()
class FCN(nn.Module):
def __init__(self, n_class=22):
super(FCN, self).__init__()
self.features_123 = nn.Sequential(
# conv1
nn.Conv2d(3, 64, 3, padding=100),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True), # 1/2
# conv2
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True), # 1/4
# conv3
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True), # 1/8
)
self.features_4 = nn.Sequential(
# conv4
nn.Conv2d(256, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True), # 1/16
)
self.features_5 = nn.Sequential(
# conv5 features
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True), # 1/32
)
self.classifier = nn.Sequential(
# fc6
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout2d(),
# fc7
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout2d(),
# score_fr
nn.Conv2d(4096, n_class, 1),
)
self.score_feat3 = nn.Conv2d(256, n_class, 1)
self.score_feat4 = nn.Conv2d(512, n_class, 1)
self.upscore = nn.ConvTranspose2d(n_class, n_class, 16, stride=8,
bias=False)
self.upscore_4 = nn.ConvTranspose2d(n_class, n_class, 4, stride=2,
bias=False)
self.upscore_5 = nn.ConvTranspose2d(n_class, n_class, 4, stride=2,
bias=False)
def forward(self, x):
feat3 = self.features_123(x) #1/8
feat4 = self.features_4(feat3) #1/16
feat5 = self.features_5(feat4) #1/32
score5 = self.classifier(feat5)
upscore5 = self.upscore_5(score5)
score4 = self.score_feat4(feat4)
score4 = score4[:, :, 5:5+upscore5.size()[2], 5:5+upscore5.size()[3]].contiguous()
score4 += upscore5
score3 = self.score_feat3(feat3)
upscore4 = self.upscore_4(score4)
score3 = score3[:, :, 9:9+upscore4.size()[2], 9:9+upscore4.size()[3]].contiguous()
score3 += upscore4
h = self.upscore(score3)
h = h[:, :, 28:28+x.size()[2], 28:28+x.size()[3]].contiguous()
return h
def init_vgg16(self, vgg16, copy_fc8=True, init_upscore=True):
for l1, l2 in zip(vgg16.features, [self.features_123,self.features_4,self.features_5]):
if (isinstance(l1, nn.Conv2d) and
isinstance(l2, nn.Conv2d)):
assert l1.weight.size() == l2.weight.size()
assert l1.bias.size() == l2.bias.size()
l2.weight.data = l1.weight.data
l2.bias.data = l1.bias.data
for i1, i2 in zip([0, 3], [0, 3]):
l1 = vgg16.classifier[i1]
l2 = self.classifier[i2]
l2.weight.data = l1.weight.data.view(l2.weight.data.size())
l2.bias.data = l1.bias.data.view(l2.bias.data.size())
n_class = self.classifier[6].weight.size()[0]
if copy_fc8:
l1 = vgg16.classifier[6]
l2 = self.classifier[6]
l2.weight.data = l1.weight.data[:n_class, :].view(l2.weight.size())
l2.bias.data = l1.bias.data[:n_class]
if init_upscore:
# initialize upscore layer
c1, c2, h, w = self.upscore.weight.data.size()
assert c1 == c2 == n_class
assert h == w
weight = get_upsample_filter(h)
self.upscore.weight.data =
weight.view(1, 1, h, w).repeat(c1, c2, 1, 1)
c1, c2, h, w = self.upscore_4.weight.data.size()
assert c1 == c2 == n_class
assert h == w
weight = get_upsample_filter(h)
self.upscore_4.weight.data =
weight.view(1, 1, h, w).repeat(c1, c2, 1, 1)
c1, c2, h, w = self.upscore_5.weight.data.size()
assert c1 == c2 == n_class
assert h == w
weight = get_upsample_filter(h)
self.upscore_5.weight.data =
weight.view(1, 1, h, w).repeat(c1, c2, 1, 1)
if __name__ == "__main__":
x = torch.zeros(1, 3, 640, 640)
model = FCN()
y = model(x)
print(y.shape)
论文通过在PASCAL VOC 2012和MS COCO数据集上的实验验证了FCN的有效性。与传统的方法相比,FCN在语义分割任务上取得了更好的结果,不仅提高了分割的准确性,而且还能够处理不同大小的输入图像。此外,FCN还可以通过fine-tuning的方式应用于其他任务,例如目标检测和图像分割。
创新&不足
创新点:
- 全卷积神经网络架构:传统的卷积神经网络(CNN)只能输出一个固定大小的向量,而全卷积神经网络(FCN)可以输出与输入图像大小相同的特征图,从而实现像素级别的语义分割。
- 上采样和跳跃连接技术:FCN使用上采样技术将特征图放大到与输入图像相同的大小,同时使用跳跃连接技术将不同尺度的特征信息融合起来,从而提高分割的准确性。
- 可迁移性:FCN可以通过fine-tuning的方式应用于其他任务,例如目标检测和图像分割。
不足之处:
- 训练时间较长:FCN的训练时间较长,需要大量的计算资源和时间。
- 模型复杂度高:FCN的模型复杂度较高,需要更多的参数和计算资源。
- 对小目标的分割效果不佳:FCN在处理小目标的分割时效果不佳,这可能是因为FCN没有充分考虑小目标的特征信息。
- 对类别不平衡的数据集效果不佳:FCN在处理类别不平衡的数据集时效果不佳,这可能是因为FCN没有充分考虑类别之间的差异。
FCN网络在PASCAL上产生状态最先进的性能。左栏显示了我们性能最高的网络FCN-8s的输出。第二张图显示了Hariharan等人先前最先进的系统产生的分割。注意恢复的精细结构(第一行),分离紧密交互对象的能力(第二行),以及对闭塞器的鲁棒性(第三行)。第四行显示了一个失败的案例:网络将船上的救生衣视为人。

影响和意义
该论文提出了一种全卷积网络(简称FCN)的方法,将传统的卷积神经网络(Convolutional Neural Networks,简称CNN)应用到语义分割问题中。这种全卷积网络可以对整个图像进行像素级别的分类,实现了端到端的语义分割。相比于传统的基于CNN的分类方法,FCN可以输出与输入图像大小相同的分割结果,提高了分割的准确性和效率。
其次,FCN的提出也启示了语义分割领域在模型设计和优化方面的改进。在FCN中,作者使用了反卷积层(Deconvolutional Layer)和池化层的反操作(Upsampling),将低分辨率的特征图还原到原始图像大小,从而得到像素级别的分割结果。这种方法不仅可以提高分割的准确性,还可以减少参数数量和计算量,提高模型的效率。
此外,FCN的应用也促进了语义分割领域的发展和应用。通过FCN,可以实现对自然图像、医学图像、遥感图像等不同领域的图像进行语义分割,为图像分析、识别、理解等应用提供了重要的支持和参考。同时,FCN也为其他相关领域的研究和应用提供了借鉴和启示,如目标检测、图像生成、视频分割等。
