持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第28天,StackGAN、StackGAN++、HDGAN;
感兴趣可以深入查看专栏:文本生成图像专栏
2.2、扩散模型 :Diffusion Model

不同于 VQ-VAE,VQ-GAN,扩散模型是当今文本生成图像领域的核心方法,当前最知名也最受欢迎的文本生成图像模型 Stable Diffusion,Disco-Diffusion,Mid-Journey,DALL-E2 等等,均基于扩散模型。
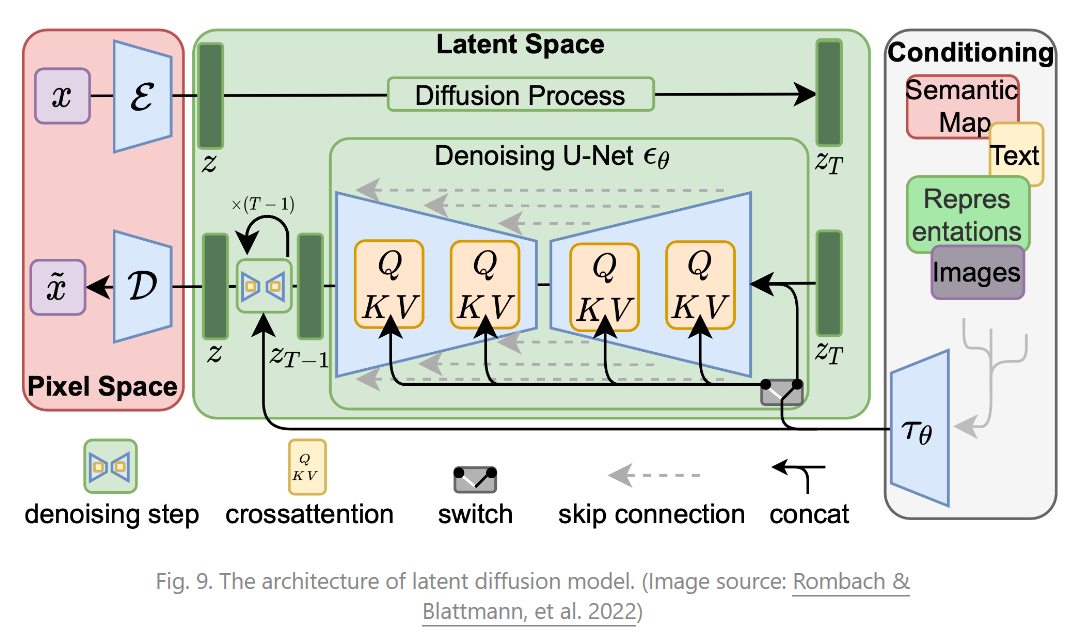
在扩散模型中,主要有两个过程组成,前向扩散过程,反向去噪过程,前向扩散过程主要是将一张图片变成随机噪音,而逆向去噪过程则是将一张随机噪音的图片还原为一张完整的图片,原理:由浅入深理解扩散模型(Diffusion Model)

扩散过程从右向左(X0=>XtX_0 =>X_t)对图片逐渐加噪,X0X_0表示从真实数据集中采样得到的一张图片,当t足够大时,XtX_t变为高斯分布。其本质就是在原始图像上添加噪音,通过 T 步迭代,最终将原始图片的分布变成标准高斯分布 ,而重要的事,每一步噪音都是已知的,即q(Xt∣Xt−1)q(X_t | X_t-1)是已知的(因为知道图像t-1,知道噪声数据),根据马尔科夫过程的性质,可以递归得到q(Xt∣X0)q(X_t |X_0),得到XtX_t。
逆扩散过程从左向右(Xt=>X0X_t =>X_0)对图片逐渐降噪,如果我们能够在给定XtX_t条件下知道Xt−1X_{t-1},我们就可以逐步从XtX_t推出X0X_0,即就可以从噪声推导出一张图像。要达到这种,我们要知道q(Xt∣Xt−1)q(X_t | X_t-1),即如何从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。显然我们很难知道q(Xt∣Xt−1)q(X_t | X_t-1),于是我们使用p(Xt∣Xt−1)p(X_t | X_t-1)来近似q(Xt∣Xt−1)q(X_t | X_t-1),p(Xt∣Xt−1)p(X_t | X_t-1)就是我们要训练的网络。我们可以使用q(Xt∣Xt−1)q(X_t | X_t-1)来指导p(Xt∣Xt−1)p(X_t | X_t-1)的训练,在完成训练之后,训练好的模型就可以通过不断的「减去」模型预测的噪音,完成逆扩散步骤,逐渐的生成一张完整的图片。
直观上理解,扩散模型其实是通过一个神经网络 ,来预测每一步扩散模型中所添加的噪音。
扩散模型在实现文本生成图像任务中,主要有以下策略:
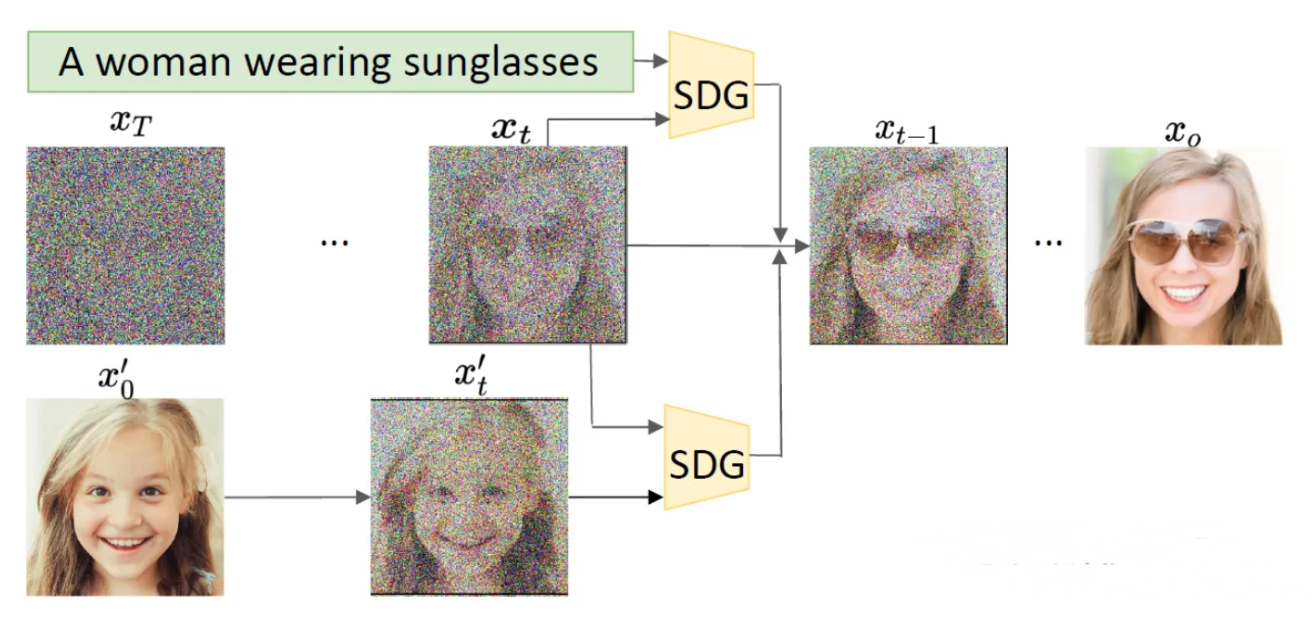
- Semantic Diffusion Guidance(以文本描述作为语义引导)通过使用引导函数来注入语义输入(此时文本可以看成一种分类器或者判别器),以指导无条件扩散模型的采样过程,这使得扩散模型中的生成更加可控,并为语言和图像引导提供了统一的公式。在逆向过程的每一步,用一个文本条件对生成的过程进行引导,基于文本和图像之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样

- Classifier-Free Diffusion Guidence:前文额外引入一个网络来指导,推理的时候比较复杂,且将引导条件作为模型的输入效果其实一般。Classifier-Free Diffusion Guidence核心思路是共同训练有条件和无条件扩散模型,并发现将两者进行组合,可以得到样本质量和多样性之间的权衡。这个方法一个很大的优点是,不需要重新训练扩散模型,只需要在前馈时加入引导既能实现相应的生成效果。应用有:GLIDE、DALL·E 2、Imagen等
- …
2.3、基于Transformer的自回归方法
Transformer模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用Transformer进行自回归图像生成。生成图像的合理性表明,Transformer模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。Transformer整体主要分为Encoder和Decoder两大部分,利用多头自注意力机制进行编码和解码。但其训练成本高,推理时间较长,且强大而有趣的模型一直未开源。
Transformer在实现文本生成图像上,大概有以下策略:
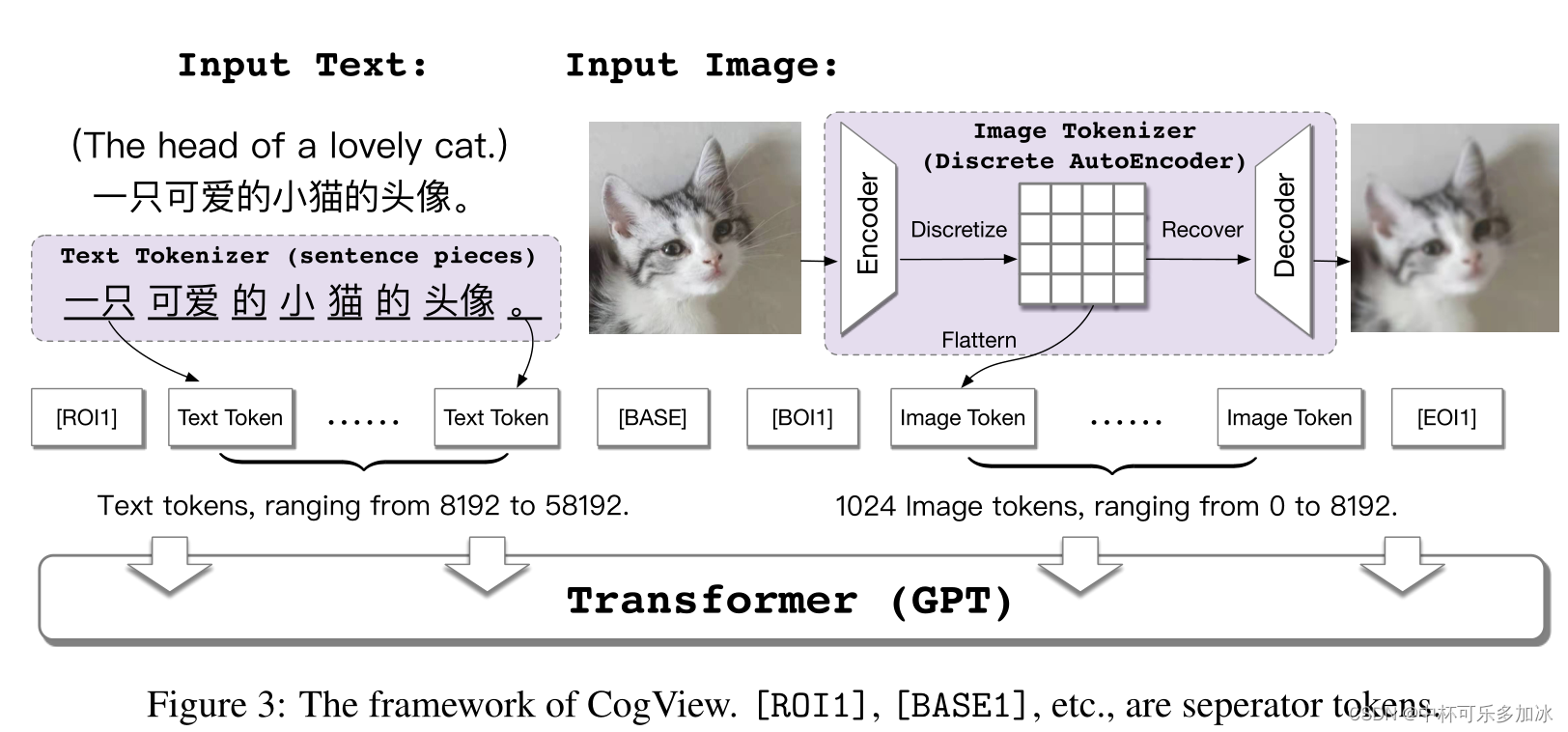
- Transformer和VQ-VAE(矢量量化变分自动编码器)进行结合,首先将文本部分转换成token,利用的是已经比较成熟的SentencePiece模型;然后将图像部分通过一个离散化的AE(Auto-Encoder)转换为token,将文本token和图像token拼接到一起,之后输入到GPT模型中学习生成图像。训练后,在处理文本图像生成类任务时,模型会通过计算一个Caption Score对生成图像进行排序,从而选择与文本最为匹配的图像作为结果:如CogView
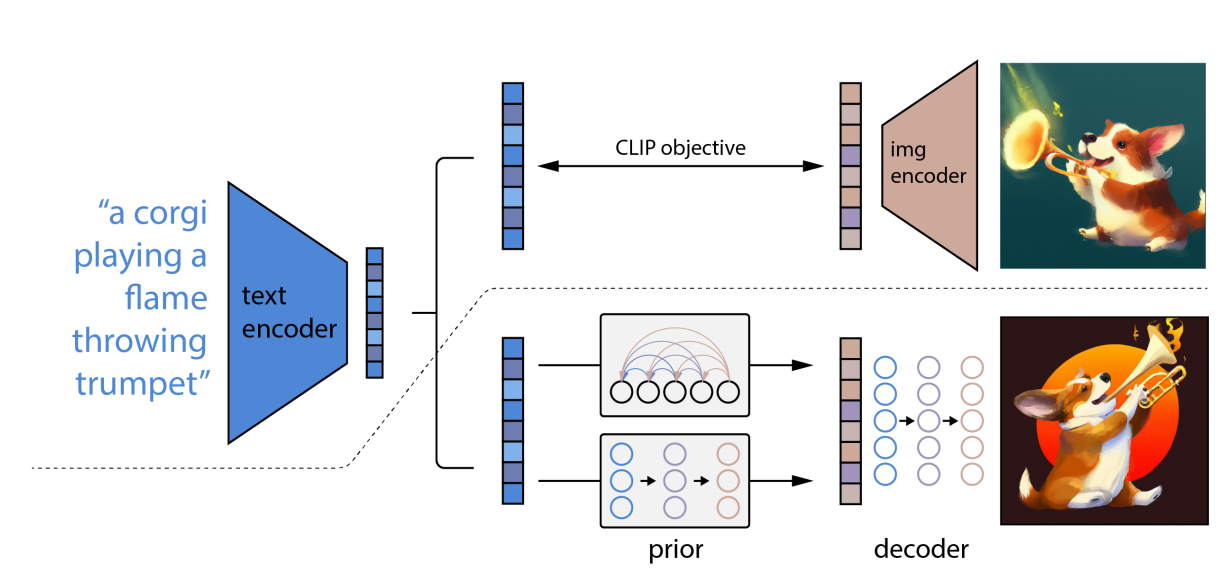
- Transformer和CLIP结合。首先对于一幅没有文本标签的图像,使用 CLIP 的图像编码器,在语言-视觉(language-vision)联合嵌入空间中提取图像的 embedding。接着,将图像转换为 VQGAN 码本空间(codebook space)中的一系列离散标记(token)。也就是将图像以与自然语言相同的方式进行表示,方便后续使用 Transformer 进行处理。其中,充当 image tokenizer 角色的 VQGAN 模型,可以使用手里的无标记图像数据集进行训练。最后,再训练一个自回归 Transformer,用它来将图像标记从 Transformer 的语言-视觉统一表示中映射出对应图像。经过这样的训练后,面对一串文本描述,Transformer 就可以根据从 CLIP 的文本编码器中提取的文本嵌入(text embedding)生成对应的图像标记(image tokens)了。如:CLIP-GEN、DALL·E、DALL·E 2
- …
2.4、基于对比的图片-文本的跨模态预训练模型:CLIP
CLIP(Contrastive Language-Image Pre-Training,简称 CLIP) 模型严格来说是一种辅助模型,是 OpenAI 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,CLIP 最初是一个单独的辅助模型,用于对 DALL·E 的结果进行排序。
对比模型可以给来自同一对的图像和文本产生高相似度得分,而对不匹配的文本和图像产生低分。

该模型由两个编码器组成:一个用于文本,另一个用于图像:
图像编码器:用于将图像映射到特征空间;
文本编码器:用于将文本映射到相同的特征空间。
原理其实很简单:为了对image和text建立联系,首先分别对image和text进行特征提取,image特征提取的backbone可以是resnet系列模型也可以是VIT系列模型,text特征提取目前一般采用bert模型,特征提取之后,由于做了normalize,直接相乘来计算余弦距离,同一pair对的结果趋近于1,不同pair对的结果趋近于0,因为就可以采用对比损失loss(info-nce-loss),熟悉这个loss的同学应该都清楚,这种计算loss方式效果与batch size有很大关系,一般需要比较大的batch size才能有效果。
CLIP可以理解成一种多模态pretrain 方式,为文本和图像在特征域进行对齐。

但CLIP采取了4亿的图像文本对的数据集,但这4亿的图像文本对并未对外开源,且CLIP是通过庞大的数据集来尽可能的覆盖下游任务,而它在未见过的数据上表现非常不理想,其不非常侧重算法上的创新,而是采集了大量的数据以及使用了大量的训练资源(592 个 V100 + 18天 和 256 个 V100 + 12天)。
CLIP主要作为辅助模型在文本生成图像中应用,比如GAN+CLIP(如FuseDream)、Diffusion Model +CLIP (如GLIDE、DALL·E )、Transformer+CLIP(如CLIP-GEN、DALL·E 2)
参考
- What are Diffusion Models?:lilianweng.github.io/posts/2021-…
- 扩散模型(Diffusion Model)——由浅入深的理解
- 基于扩散模型的文本引导图像生成算法:zhuanlan.zhihu.com/p/505257039
- 扩散模型与其在文本生成图像领域的应用:zhuanlan.zhihu.com/p/546311167
- 连接文本和图像的第一步:CLIP:zhuanlan.zhihu.com/p/427740816
