对话记忆是指聊天机器人如何以对话方式响应多个查询。它使对话连贯,并且如果没有它,每个查询都将被视为完全独立的输入,而不考虑过去的交互。
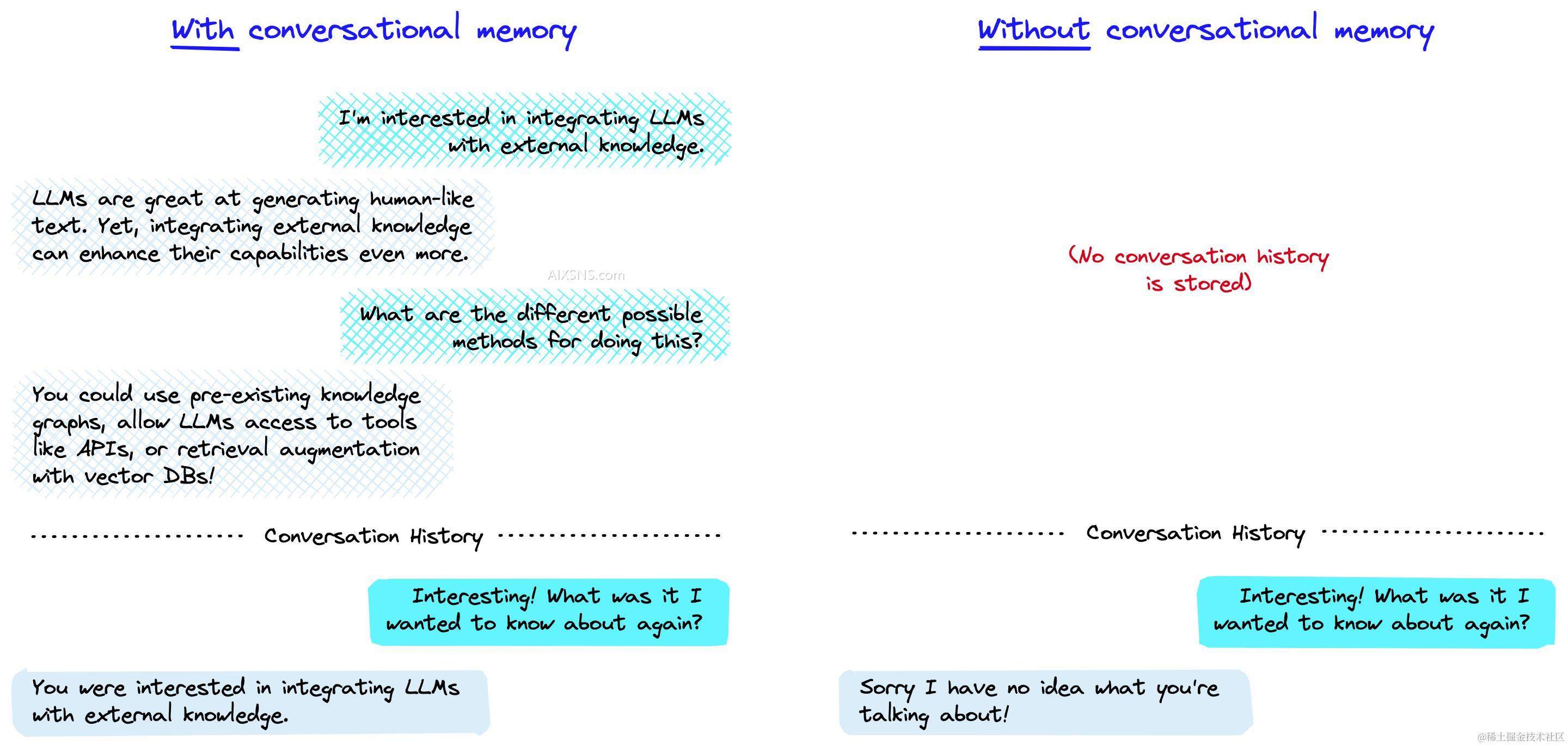
这种记忆使得大型语言模型(LLM)能够记住与用户之前的互动。默认情况下,LLMs是无状态的,这意味着每个传入的查询都是独立处理的,不考虑其他互动。对于一个无状态的代理,唯一存在的是当前的输入,没有其他信息。
有许多应用程序在其中记住之前的互动非常重要,比如聊天机器人。对话记忆允许我们做到这一点。
有几种方法可以实现对话记忆。在LangChain的背景下,它们都是基于ConversationChain构建的。
ConversationChain(对话链)
我们可以通过初始化ConversationChain(对话链)开始。我们将使用OpenAI的text-davinci-003作为LLM,但也可以使用其他模型,如gpt-3.5-turbo。
from langchain import OpenAI
from langchain.chains import ConversationChain
# first initialize the large language model
llm = OpenAI(
temperature=0,
openai_api_key="OPENAI_API_KEY",
model_name="text-davinci-003"
)
# now initialize the conversation chain
conversation = ConversationChain(llm=llm)
我们可以这样查看ConversationChain使用的提示模板:
In[8]:
print(conversation.prompt.template)
Out[8]:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:
在这里,提示通过告诉模型以下内容是一个人类(我们)和一个AI(text-davinci-003)之间的对话来引导模型。提示试图通过陈述以下内容来减少幻觉(模型编造事物的情况):
“If the AI does not know the answer to a question, it truthfully says it does not know.”
这有助于减少幻觉的发生,但并不能完全解决幻觉的问题,但我们将把这个问题留到未来章节讨论。
在初始提示之后,我们看到两个参数;{history} 和 {input}。{input} 是我们将放置最新的人类查询的地方;它是输入到聊天机器人文本框的输入内容:
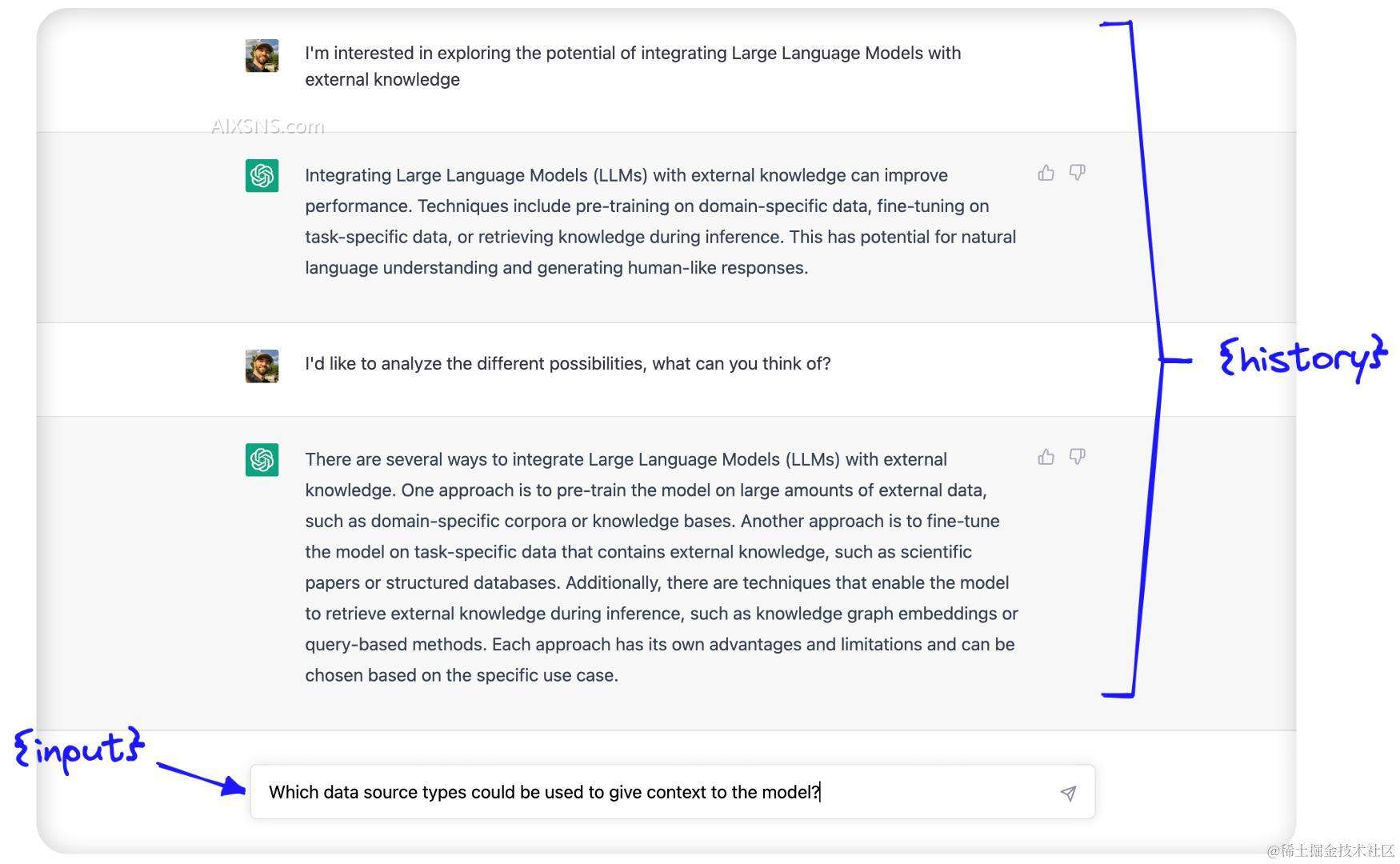
{history} 是用于使用对话记忆的地方。在这里,我们提供了关于人类和AI之间对话历史的信息。
这两个参数——{history} 和 {input}——传递给了我们刚刚看到的提示模板中的LLM,而我们(希望如此)返回的输出只是对话的预测继续部分。
对话记忆的形式
我们可以在ConversationChain中使用多种类型的对话记忆。它们修改传递给{history}参数的文本。
对话缓冲记忆
ConversationBufferMemory是LangChain中最直接的对话记忆形式。正如我们上面所描述的,过去人类和AI之间的对话的原始输入以其原始形式传递到{history}参数中。
In[11]:
from langchain.chains.conversation.memory import ConversationBufferMemory
conversation_buf = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
In[32]:
conversation_buf("Good morning AI!")
Out[32]:
{'input': 'Good morning AI!',
'history': '',
'response': " Good morning! It's a beautiful day today, isn't it? How can I help you?"}
我们返回了对话代理的第一个响应。让我们继续对话,编写只有在考虑对话历史时LLM才能回答的提示。我们还添加了一个count_tokens函数,以便我们可以查看每次交互使用了多少标记。
In[6]:
from langchain.callbacks import get_openai_callback
def count_tokens(chain, query):
with get_openai_callback() as cb:
result = chain.run(query)
print(f'Spent a total of {cb.total_tokens} tokens')
return result
In[33]:
count_tokens(
conversation_buf,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
Out[33]:
Spent a total of 179 tokens
Out[33]:
' Interesting! Large Language Models are a type of artificial intelligence that can process natural language and generate text. They can be used to generate text from a given context, or to answer questions about a given context. Integrating them with external knowledge can help them to better understand the context and generate more accurate results. Is there anything else I can help you with?'
In[34]:
count_tokens(
conversation_buf,
"I just want to analyze the different possibilities. What can you think of?"
)
Out[34]:
Spent a total of 268 tokens
Out[34]:
' Well, integrating Large Language Models with external knowledge can open up a lot of possibilities. For example, you could use them to generate more accurate and detailed summaries of text, or to answer questions about a given context more accurately. You could also use them to generate more accurate translations, or to generate more accurate predictions about future events.'
In[35]:
count_tokens(
conversation_buf,
"Which data source types could be used to give context to the model?"
)
Out[35]:
Spent a total of 360 tokens
Out[35]:
' There are a variety of data sources that could be used to give context to a Large Language Model. These include structured data sources such as databases, unstructured data sources such as text documents, and even audio and video data sources. Additionally, you could use external knowledge sources such as Wikipedia or other online encyclopedias to provide additional context.'
In[36]:
count_tokens(
conversation_buf,
"What is my aim again?"
)
Out[36]:
Spent a total of 388 tokens
Out[36]:
' Your aim is to explore the potential of integrating Large Language Models with external knowledge.'
LLM显然可以记住对话的历史。让我们看看ConversationBufferMemory是如何存储这个对话历史的:
In[37]:
print(conversation_buf.memory.buffer)
Out[37]:
Human: Good morning AI!
AI: Good morning! It's a beautiful day today, isn't it? How can I help you?
Human: My interest here is to explore the potential of integrating Large Language Models with external knowledge
AI: Interesting! Large Language Models are a type of artificial intelligence that can process natural language and generate text. They can be used to generate text from a given context, or to answer questions about a given context. Integrating them with external knowledge can help them to better understand the context and generate more accurate results. Is there anything else I can help you with?
Human: I just want to analyze the different possibilities. What can you think of?
AI: Well, integrating Large Language Models with external knowledge can open up a lot of possibilities. For example, you could use them to generate more accurate and detailed summaries of text, or to answer questions about a given context more accurately. You could also use them to generate more accurate translations, or to generate more accurate predictions about future events.
Human: Which data source types could be used to give context to the model?
AI: There are a variety of data sources that could be used to give context to a Large Language Model. These include structured data sources such as databases, unstructured data sources such as text documents, and even audio and video data sources. Additionally, you could use external knowledge sources such as Wikipedia or other online encyclopedias to provide additional context.
Human: What is my aim again?
AI: Your aim is to explore the potential of integrating Large Language Models with external knowledge.
我们可以看到缓冲保存了聊天历史中的每一次互动。这种方法有一些优点和缺点。简而言之,它们是:
| Pros | Cons |
|---|---|
| Storing everything gives the LLM the maximum amount of information | More tokens mean slowing response times and higher costs |
| Storing everything is simple and intuitive | Long conversations cannot be remembered as we hit the LLM token limit (4096 tokens for text-davinci-003 and gpt-3.5-turbo) |
ConversationBufferMemory是一个很好的开始选项,但受到保存每次互动的存储限制。让我们看看其他可以帮助解决这个问题的选项。
对话摘要记忆
使用ConversationBufferMemory,我们很快就使用了大量的标记,甚至超出了当前最先进的LLMs的上下文窗口限制。
为了避免过多的标记使用,我们可以使用ConversationSummaryMemory。正如其名称所示,这种形式的记忆在传递给{history}参数之前对对话历史进行了总结。
我们可以这样初始化ConversationChain,使用总结记忆:
from langchain.chains.conversation.memory import ConversationSummaryMemory
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)
当使用ConversationSummaryMemory时,我们需要将一个LLM传递给该对象,因为总结是由一个LLM提供支持的。我们可以在这里看到用于此操作的提示:
In[19]:
print(conversation_sum.memory.prompt.template)
Out[19]:
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
Current summary:
{summary}
New lines of conversation:
{new_lines}
New summary:
使用这个方法,我们可以总结每一次新的互动,并将它添加到所有过去互动的“运行摘要”中。让我们再次进行一次利用这种方法的对话。
In[40]:
# without count_tokens we'd call `conversation_sum("Good morning AI!")`
# but let's keep track of our tokens:
count_tokens(
conversation_sum,
"Good morning AI!"
)
Out[40]:
Spent a total of 290 tokens
Out[40]:
" Good morning! It's a beautiful day today, isn't it? How can I help you?"
In[41]:
count_tokens(
conversation_sum,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
Out[41]:
Spent a total of 440 tokens
Out[41]:
" That sounds like an interesting project! I'm familiar with Large Language Models, but I'm not sure how they could be integrated with external knowledge. Could you tell me more about what you have in mind?"
In[42]:
count_tokens(
conversation_sum,
"I just want to analyze the different possibilities. What can you think of?"
)
Out[42]:
Spent a total of 664 tokens
Out[42]:
' I can think of a few possibilities. One option is to use a large language model to generate a set of candidate answers to a given query, and then use external knowledge to filter out the most relevant answers. Another option is to use the large language model to generate a set of candidate answers, and then use external knowledge to score and rank the answers. Finally, you could use the large language model to generate a set of candidate answers, and then use external knowledge to refine the answers.'
In[43]:
count_tokens(
conversation_sum,
"Which data source types could be used to give context to the model?"
)
Out[43]:
Spent a total of 799 tokens
Out[43]:
' There are many different types of data sources that could be used to give context to the model. These could include structured data sources such as databases, unstructured data sources such as text documents, or even external APIs that provide access to external knowledge. Additionally, the model could be trained on a combination of these data sources to provide a more comprehensive understanding of the context.'
In[44]:
count_tokens(
conversation_sum,
"What is my aim again?"
)
Out[44]:
Spent a total of 853 tokens
Out[44]:
' Your aim is to explore the potential of integrating Large Language Models with external knowledge.'
在这种情况下,总结包含足够的信息,以使LLM“记住”我们最初的目标。我们可以像这样查看总结的原始形式:
In[45]:
print(conversation_sum.memory.buffer)
Out[45]:
The human greeted the AI with a good morning, to which the AI responded with a good morning and asked how it could help. The human expressed interest in exploring the potential of integrating Large Language Models with external knowledge, to which the AI responded positively and asked for more information. The human asked the AI to think of different possibilities, and the AI suggested three options: using the large language model to generate a set of candidate answers and then using external knowledge to filter out the most relevant answers, score and rank the answers, or refine the answers. The human then asked which data source types could be used to give context to the model, to which the AI responded that there are many different types of data sources that could be used, such as structured data sources, unstructured data sources, or external APIs. Additionally, the model could be trained on a combination of these data sources to provide a more comprehensive understanding of the context. The human then asked what their aim was again, to which the AI responded that their aim was to explore the potential of integrating Large Language Models with external knowledge.
这次对话中使用的标记数量比使用ConversationBufferMemory多,所以使用ConversationSummaryMemory是否有任何优势呢?
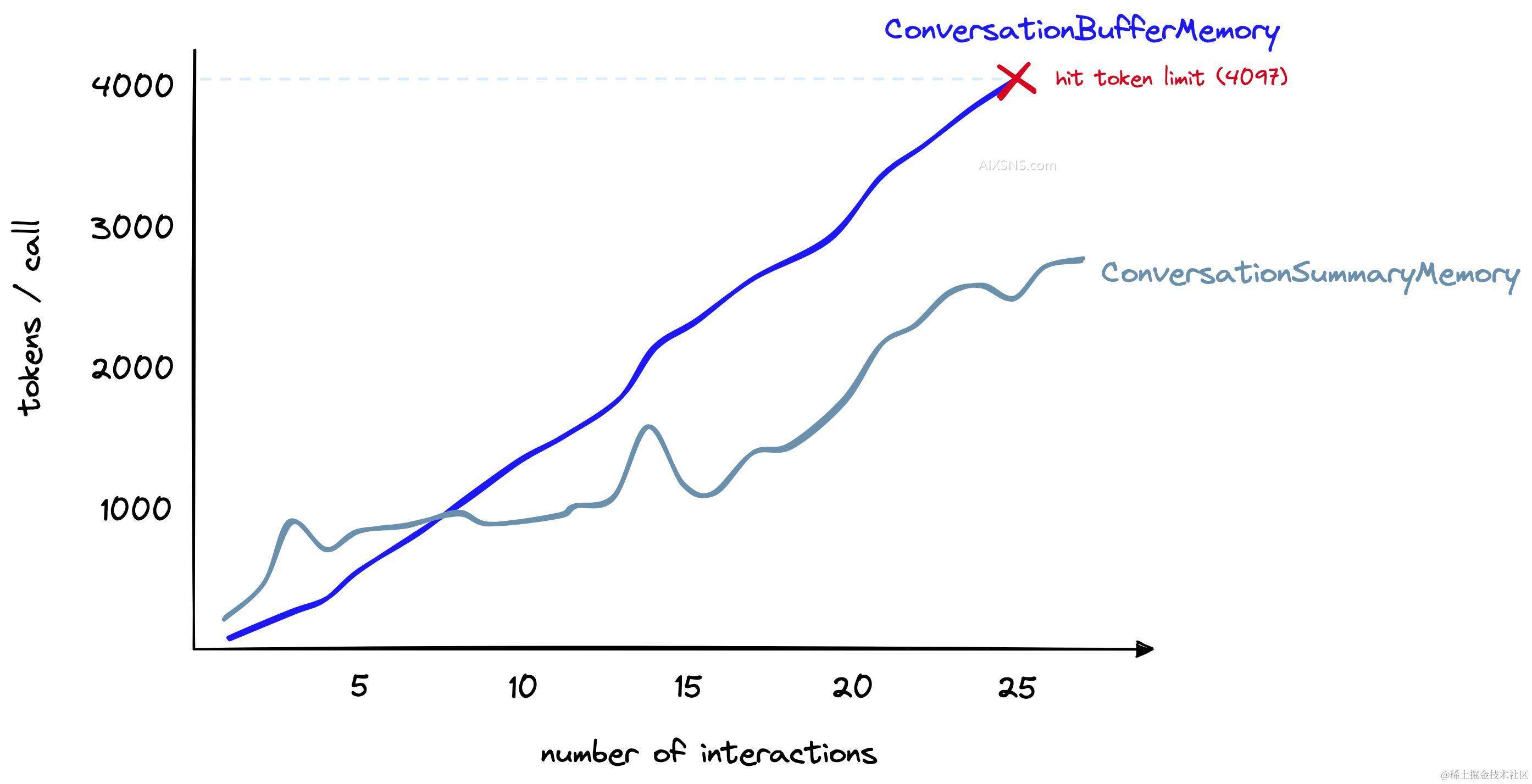
对于更长的对话来说,是的。在这里,我们有一个较长的对话。如上所示,摘要内存最初使用的标记要多得多。然而,随着对话的进行,总结的方法增长速度较慢。相比之下,缓冲内存会随着聊天中的标记数量线性增长。
我们可以总结ConversationSummaryMemory的优缺点如下:
| Pros | Cons |
|---|---|
| Shortens the number of tokens for long conversations. | Can result in higher token usage for smaller conversations |
| Enables much longer conversations | Memorization of the conversation history is wholly reliant on the summarization ability of the intermediate summarization LLM |
| Relatively straightforward implementation, intuitively simple to understand | Also requires token usage for the summarization LLM; this increases costs (but does not limit conversation length) |
对于预期有长对话的情况,对话总结是一个不错的方法。然而,它仍然基本上受到标记限制的限制。经过一段时间后,我们仍然会超出上下文窗口的限制。
对话缓冲窗口内存
“ConversationBufferWindowMemory” 的作用与之前的 “缓冲内存” 相同,但它在内存中添加了一个窗口。这意味着我们只保留一定数量的过去交互,然后将其“遗忘”。我们使用它的方式如下:
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferWindowMemory(k=1)
)
在这个示例中,我们设置了 k=1 — 这意味着窗口会记住人类和人工智能之间的最新一次交互。也就是最新的人类回复和最新的人工智能回复。我们可以看到这个效果如下:
In[61]:
count_tokens(
conversation_bufw,
"Good morning AI!"
)
Out[61]:
Spent a total of 85 tokens
Out[61]:
" Good morning! It's a beautiful day today, isn't it? How can I help you?"
In[62]:
count_tokens(
conversation_bufw,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
Out[62]:
Spent a total of 178 tokens
Out[62]:
' Interesting! Large Language Models are a type of artificial intelligence that can process natural language and generate text. They can be used to generate text from a given context, or to answer questions about a given context. Integrating them with external knowledge can help them to better understand the context and generate more accurate results. Do you have any specific questions about this integration?'
In[63]:
count_tokens(
conversation_bufw,
"I just want to analyze the different possibilities. What can you think of?"
)
Out[63]:
Spent a total of 233 tokens
Out[63]:
' There are many possibilities for integrating Large Language Models with external knowledge. For example, you could use external knowledge to provide additional context to the model, or to provide additional training data. You could also use external knowledge to help the model better understand the context of a given text, or to help it generate more accurate results.'
In[64]:
count_tokens(
conversation_bufw,
"Which data source types could be used to give context to the model?"
)
Out[64]:
Spent a total of 245 tokens
Out[64]:
' Data sources that could be used to give context to the model include text corpora, structured databases, and ontologies. Text corpora provide a large amount of text data that can be used to train the model and provide additional context. Structured databases provide structured data that can be used to provide additional context to the model. Ontologies provide a structured representation of knowledge that can be used to provide additional context to the model.'
In[65]:
count_tokens(
conversation_bufw,
"What is my aim again?"
)
Out[65]:
Spent a total of 186 tokens
Out[65]:
' Your aim is to use data sources to give context to the model.'
在对话结束时,当我们问“我的目标是什么?”时,答案包含在三次交互前的人类回应中。由于我们只保留了最近的一次交互(k=1),模型已经忘记了,无法给出正确的答案。
我们可以这样看到模型的有效“记忆”:
In[66]:
bufw_history = conversation_bufw.memory.load_memory_variables(
inputs=[]
)['history']
In[67]:
print(bufw_history)
Out[67]:
Human: What is my aim again?
AI: Your aim is to use data sources to give context to the model.
尽管这种方法不适用于记住远距离的交互,但它很擅长限制使用的标记数量 — 这是一个可以根据我们的需求增加或减少的数量。对于我们之前比较中使用的更长对话,我们可以设置 k=6,在总共27次交互后达到每次交互约1.5K标记:
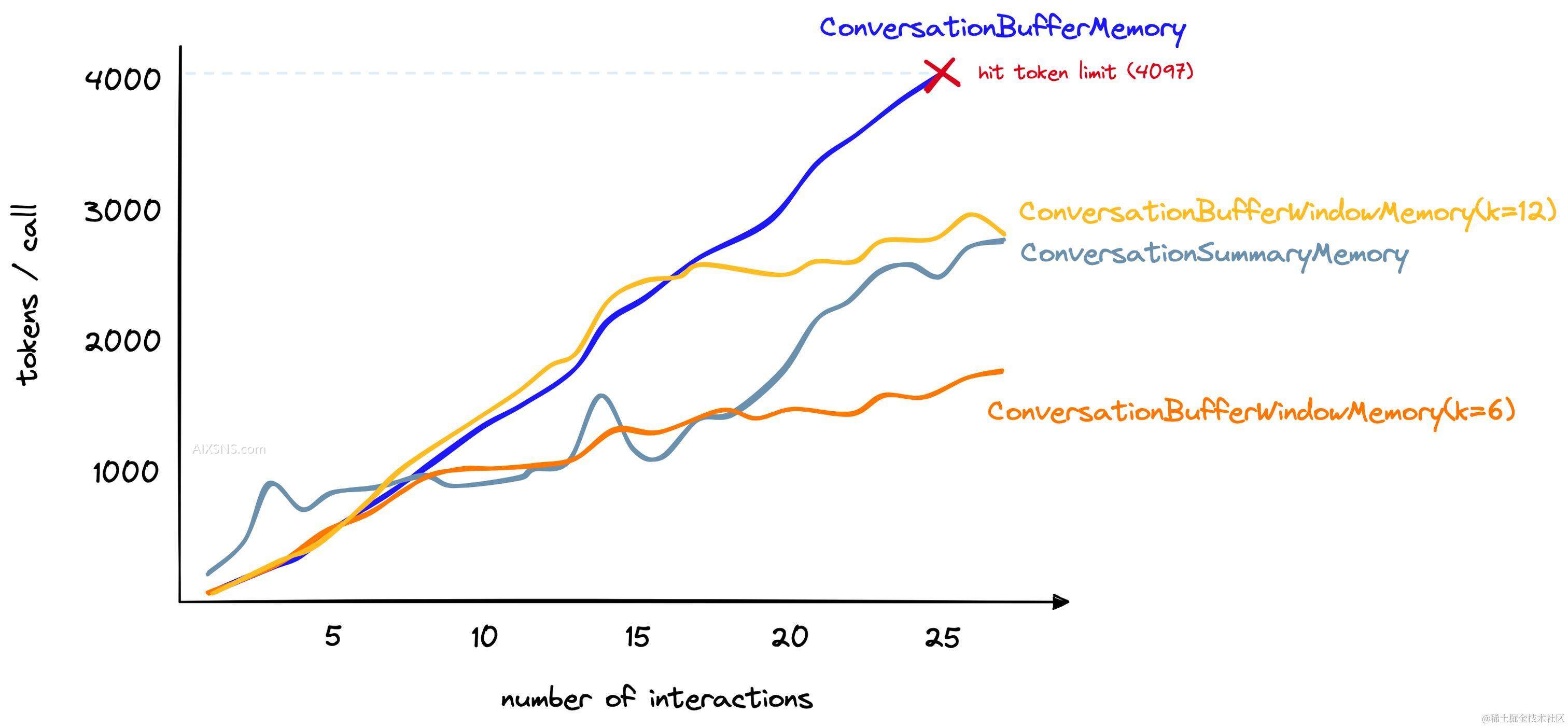
如果我们只需要最近交互的记忆,这是一个很好的选择。然而,如果需要同时考虑远距离和最近交互,还有其他选择。
对话总结缓冲内存
“ConversationSummaryBufferMemory” 是对话总结内存和对话缓冲窗口内存的混合体。它总结了对话中最早的交互,同时保留了对话中最近的标记数不超过最大标记限制。初始化如下所示:
conversation_sum_bufw = ConversationChain(
llm=llm, memory=ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=650
)
将这个方法应用到之前的对话中,我们可以将max_token_limit设置为一个较小的数字,但语言模型仍然可以记住我们之前的“目标”。
这是因为这些信息被“总结”组件捕获,尽管被“缓冲窗口”组件忽略了。
当然,这个组件的优缺点是基于其所依赖的之前的组件的混合。
| Pros | Cons |
|---|---|
| Summarizer means we can remember distant interactions | Summarizer increases token count for shorter conversations |
| Buffer prevents us from missing information from the most recent interactions | Storing the raw interactions — even if just the most recent interactions — increases token count |
尽管需要更多的调整来确定要总结和在缓冲窗口内保留的内容,但ConversationSummaryBufferMemory确实为我们提供了很大的灵活性,而且它是我们目前唯一能够记住远距离交互并以原始和最信息丰富的形式存储最近交互的记忆类型之一。
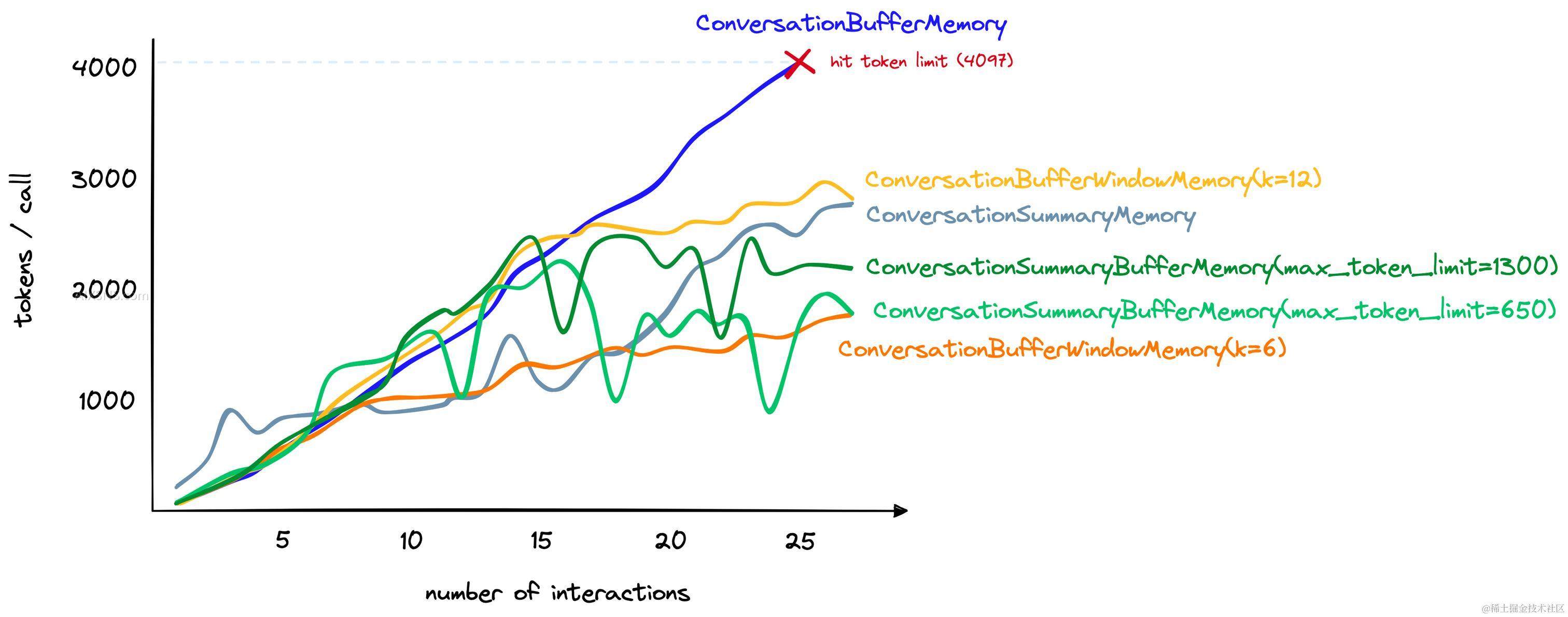
我们还可以看到,尽管包括了对过去交互的总结和最近交互的原始形式,ConversationSummaryBufferMemory的标记数量增加与其他方法相竞争。
其他记忆类型
我们在这里介绍的记忆类型非常适合入门,能够在尽量记住尽可能多的信息和最小化标记之间取得良好的平衡。
然而,我们还有其他选择,特别是ConversationKnowledgeGraphMemory和ConversationEntityMemory。我们将在接下来的章节中更详细地介绍这些不同形式的记忆。
这就是关于使用LangChain的LLMs的对话记忆的简介。正如我们所见,有很多选项可以帮助无状态的LLMs以仿佛在有状态的环境中进行交互,能够考虑和参考以前的交互。
正如提到的,还有其他形式的记忆我们可以涵盖。我们还可以实现自己的记忆模块,在同一链中使用多种类型的记忆,将它们与代理结合使用,等等。所有这些内容都将在未来的章节中介绍。
